- 第1页:NV发布第二代DX11旗舰 GTX580登场
- 第2页:30亿晶体管 打造GF100和GF110核心
- 第3页:温故而知新 复习GF100预习GF110
- 第4页:由繁化简 GF110/GF100结构组成细说
- 第5页:Fermi架构核心 新增强劲神器引擎
- 第6页:可读写缓存引入GPU 计算能力倍增
- 第7页:Fermi架构针对GPU通用计算优化
- 第8页:传承尊贵/豪华 GTX580全景赏析
- 第9页:完全拆解GTX580 PCB零距离接触
- 第10页:NV旗舰不用热管 引入均热板技术
- 第11页:大家来找茬 GTX580/GTX480外观对比
- 第12页:大家来找茬 GTX580/GTX480之PCB对比
- 第13页:GTX580测试平台及测试项目简介
- 第14页:理论性能测试-3Dmark 06
- 第15页:理论性能测试-3Dmark Vantage
- 第16页:DX9.0c游戏-星际争霸2
- 第17页:DX9.0c游戏-街头霸王4
- 第18页:DX10游戏-英雄连之前线
- 第19页:DX10游戏-孤岛危机
- 第20页:DX11游戏-异形大战铁血战士
- 第21页:DX11游戏-战地之叛逆连队2
- 第22页:DX11游戏-科林麦克雷之尘埃2
- 第23页:DX11游戏-失落星球2
- 第24页:DX11游戏-地铁2033
- 第25页:DX11游戏-潜行者之普利皮亚召唤
- 第26页:DX11游戏-汤姆克兰西之鹰击长空2
- 第27页:Tessellation测试-天堂2.1
- 第28页:PhysX游戏-蝙蝠侠之阿卡姆疯人院
- 第29页:应用性测试-Media Coder NT
- 第30页:应用性测试-超频及SLI性能测试
- 第31页:应用性测试-反锯齿性能衰减
- 第32页:应用性测试-Tessellation性能衰减
- 第33页:应用性测试-产品实际功耗考验
- 第34页:应用性测试-产品温度/噪音考验
- 第35页:百花齐放 GTX580发布厂商集体跟进
- 第36页:旗舰也有性价比产品 GTX580可以买
NV发布第二代DX11旗舰 GTX580登场
美国2010年11月08日,NVIDIA发布了第二代DirectX 11产品——GeForce GTX 580,这款产品的出现预示着NVIDIA在第一代DirectX 11产品“晚点”半年之后,经过缜密的产品发布计划将第二代DirectX 11产品与竞争对手之间距离缩短至仅20天。
GeForce GTX 580从型号命名上不难看出,它是NVIDIA第二代DirectX 11产品的顶级单芯产品,在这一点上与对手的第二代DirectX 11产品Radeon HD 6800系列迥然不同。NVIDIA继续保持8系命名型号为高端产品的方式,而AMD则经过Radeon HD 3000、Radeon HD 4000和Radeon HD 5000系列之后,在Radeon HD 6000系列上做了改变,将以Radeon HD 6900作为顶级单芯和双芯的系列名称。这样的变化会让很多不明真相的消费者,误认为Radeon HD 6870是Radeon HD 5870的接班人。

GeForce GTX 580

在NVIDIA进入DirectX 11后,第一代的产品都会被形象被各种不同实力兵种所诠释,例如GeForce GTX 480为Tank、GeForce GTX 460为Hunter,而GeForce GTS 450则为Sniper。那么GeForce GTX 580将会是什么?上图种我们看到,GeForce GTX 580依然一Tank的兵种实力展现,不过在武器装备上相比GeForce GTX 480的Tank更为先进,俨然一个Super Tank,这样的设计是否寓意着什么呢?
| GeForce GTX 580 显 卡 对 位 产 品 规 格 比 较 表 | |||||||
| 显卡型号 | GeForce GTX 580 | GeForce GTX 480 | GeForce GTX 470 | Radeon HD 6870 | Radeon HD 6850 | Radeon HD 5870 | Radeon HD 5850 |
| 市场定价 | 3999 元 | 3888 元 | 2888 元 | 1999-1899 | 1399-1299 | 3299 元 | 2399 元 |
| GPU代号 | GF110 | GF100 | GF100 | Barts | Barts | Cypress | Cypress |
| GPU工艺 | 40 nm | 40 nm | 40 nm | 40 nm | 40 nm | 40 nm | 40 nm |
| GPU晶体管 | 30 亿 | 30 亿 | 30 亿 | 17 亿 | 17 亿 | 21.5 亿 | 21.5 亿 |
| 着色器数量 | 512 | 480 | 448 | 1120 | 960 | 1600 | 1440 |
| 着色器组织 | 1D *512 | 1D *480 | 1D *448 | (1D+4D) *224 | (1D+4D) *192 | (1D+4D)*320 | (1D+4D)*288 |
| ROPs数量 | 48 | 48 | 40 | 32 | 32 | 32 | 32 |
| 纹理单元数量 | 64 | 60 | 56 | 56 | 48 | 80 | 72 |
| 核心频率 | 772 MHz | 700 MHz | 607 MHz | 900 MHz | 775 MHz | 850 MHz | 725 MHz |
| 着色器频率 | 1544 MHz | 1401 MHz | 1215 MHz | 900 MHz | 775 MHz | 850 MHz | 725 MHz |
| 理论计算能力 | 2.37 TFLOPs | 2.02 TFLOPs | 1.63 TFLOPs | 2.02 TFLOPs | 1.49 TFLOPs | 2.72 TFLOPs | 2.09 TFLOPs |
| 等效内存频率 | 4008 MHz | 3696 MHz | 3398 MHz | 4200 MHz | 4000 MHz | 4800 MHz | 4000 MHz |
| 内存位宽 | 384 bit | 384 bit | 320 bit | 256 bit | 256 bit | 256 bit | 256 bit |
| 内存带宽 | 192.4 GB/s | 177.4 GB/s | 135.9 GB/s | 134.4 GB/s | 128 GB/s | 153.6 GB/s | 128.0 GB/s |
| 内存类型 | GDDR5 | GDDR5 | GDDR5 | GDDR5 | GDDR5 | GDDR5 | GDDR5 |
| 内存容量 | 1536 MB | 1536 MB | 1280 MB | 1024 MB | 1024 MB | 1024 MB | 1024 MB |
| DX版本支持 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| HD视频技术 | PureVideo HD | PureVideo HD | PureVideo HD | UVD3 | UVD3 | UVD2 | UVD2 |
| 通用计算接口 | CUDA | CUDA | CUDA | Stream | Stream | Stream | Stream |
众所周知,基于GF100核心的产品没有一款使用了全规格核心,即使众望所归的GeForce GTX 485也被NVIDIA扼杀在谣言中。不过即使推出这样全规格的产品,很多用户都对期功耗、发热量产生了质疑。
我们通过上面的图表不难看出,GeForce GTX 580并没有使用GF100核心,而是型号为GF110的产品。但在非频率规格上,GF110无论是晶体管数量,还是其他硬件规格都惊人的与满规格GF100核心相似。例如其标配512个CUDA Core、384bit显存控制器、48个光栅处理器、64个纹理单元等等,尤其是在晶体管数量上同为30亿。“Tank”和“Super Tank”之间有何关系呢?
30亿晶体管 打造GF100和GF110核心
● 不得不说的秘密 NVIDIA GTC 2010
在今年9月的NVIDIA GTC 2010大会上,笔者被邀请前往美国参加此次盛会,同时还有幸参观了NVIDIA位于硅谷的总部。在总部参观过程中的一站为GTL(Game Test Lab)部门,这个部门是针对已发布、未发布和对手已发布的全线产品进行全面游戏性能测试,因为GTL实验室是NVIDIA“游戏之道”的一个重要环节。
而在此次GTL实验室的参观中,笔者看到了今天才发布的GeForce GTX 580,由于受限于保密协议所以不能进行报道,而且值得一提的是除了GeForce GTX 580之外,其他未发布产品也在此次参观中偶遇,也就是说NVIDIA早已有了第二代DirectX 11产品,但并没有急于发布,也许是为了保守的针对对手见机行事。

神秘产品及测试数据
在GTL实验室报道中这张被笔者“精心”涂抹的照片信息,其实就是GeForce GTX 580单卡及SLI性能的官方测试数据。
● 同为30亿晶体管 打造GF110核心
GF100核心使用了30亿晶体管“联袂打造”,而GF110同样由这个数量晶体管制造。而且GF110核心与GF100核心使用了完全相同的架构设计,也就是说无论从架构设计、规格设定还是功能均相同。那么GF110是否就是GF100的满规格产品呢?

40nm工艺的GF110-375-A1核心
GeForce GTX 580使用了台积电采用40nm工艺制造的GF110-375-A1核心,其由30亿晶体管构成,默认标配512个流处理器、48个光栅处理器、64个纹理单元和384bit显存控制器等。
虽然GeForce GTX 580为NVIDIA第二代DirectX 11产品,但是这款GF110核心实在难逃与GF100之间的关系。不仅核心架构、规格和功能上相同外,即使是核心型号上也与GeForce GTX 480的GF100-375-A1仅为一字之差。
不过GF110并非GF100核心的简单满规格产品,因为GF110是在GF100核心基础上重新设计布线,目的是修正GF100的高漏电性,从而达成低温低功耗的表现。同时GF110还优化了Z-Cull,令其实现了单周期16 位纹理双线性取样。经过这样优化后的GF100核心演变成了我们现在看到的GF110核心。

配置12颗SAMSUNG K4G10325FE-HC04显存颗粒
GeForce GTX 580显存方面配置了12颗规格为16M*32bit的SAMSUNG K4G10325FE-HC04颗粒,构成384bit/1536MB的组合。

GPU-Z软件识别情况
目前最新版本的GPU-Z仍然无法正式识别GeForce GTX 580,例如上图中很多关键参数都无法识别,同时显存颗粒还被识别为GDDR3。不过显存容量和显卡频率识别正确,显存容量为1536MB,公版默认频率为772MHz/1544MHz/4008MHz。

这张表格详细的介绍了GeForce GTX 580的硬件规格。其有512个流处理器,每32个SP构成一组SM,同时标配1个Polymoph Engine(该引擎包含重要的Tessellation单元),也就是说GF110拥有目前单芯最多的16个Tessellation单元。同时每4组SM构成一组GPC,标配一组Raster Engine。
GF110这种32个SP构成一组SM的设计,与GF104、GF106和GF108的设计48个SP构成一组SM不同,也许就单SM性能而言GF10X核心的性能更高,单并不适合旗舰的GF110和GF100使用,因为更多的CUDA Core被统一调度,架构设计越扁平化效率越高。
GeForce GTX 580的TDP为244瓦,略低于GeForce GTX 480网上传闻的250瓦或者275瓦。
温故而知新 复习GF100预习GF110
温故而知新 复习GF100预习GF110
前文我们已经提及,GF110这款核心采用了与GF100完全相同的架构设计、功能设计,甚至晶体管数量也完全相同,那么就GF110核心架构而言,我们复习GF100就会对其了解的更快一些,因为二者之间即使不是同一核心,也可看做双胞胎的关系。
● 温故而知新 复习GF100预习GF110
我们知道直接影响性能的参数当属硬件规格和产品频率,但是高规格和高频率的实现必须由晶体管来足见完成,GT200第一批产品是一个采用65nm制程的14亿晶体管庞然大物,由于成本、性能等各方面的考虑,在2009年1月推出了55nm制程的GT200核心,但核心面积依然庞大。反观对手AMD,在核心制程上一直走在前沿,例如Radeon HD 5000系列直接使用40nm制程,即使最高规格的RV870拥有21.5亿核心面积也仅为330mm2。

Fermi GF100设计架构
众所周知,Fermi为了达到更高的性能将使用30亿晶体管,如果NVIDIA一如既往的保守采用成熟的低制程,将会重蹈GT200覆辙,所以Fermi方面NVIDIA从设计之初就决定使用40nm工艺。虽然出发点是好的,但无奈GPU代工生产方台积电良率过低,彻底延误了NVIDIA下一代产品的推进进度。
不过无论怎样还是让我们了解一下Fermi GF100的全规格核心硬件规格:
①标配512个CUDA Cores(也就是我们常说的流处理器);
②拥有16个Polymorph Engines(下文会对其进行简介);
③拥有4个Raster Engines(下文会对其进行简介);
④拥有64个纹理单元;
⑤拥有48个ROP单元(光栅处理器);
⑥拥有384位GDDR5内存控制器。
● GF100整体架构
GF100 GPU基于图形处理团簇(翻译为GPC),可扩展流阵列多处理器(SM)和内存控制器(MC)。一个完整GF100实现四个GPC,16个SM和6个内存控制器。通过对GPC的开启和关闭,对SM和内存控制器不同的配置,可以划分出满足不同价位的产品。所以我们也可以称GF100为一个4 GPC核心的GPU。

Fermi架构GF100功能单元分布
图中我们可以看到GF100的总线接口、GigaThread线程调度器、四个完整的GPC单元、六个内存控制器、六个ROP簇和768KB二级缓存。每个GPC单元包含四个多边形引擎。六个ROP簇紧邻二级缓存。
CPU的命令通过Host Interface总线接口传输到GPU。在GigaThread引擎会从系统内存提取指定数据,并把它们拷贝到指定的显存。 GF100集成了6个64位GDDR5内存控制器(共计384位),以便获得高带宽和低延迟。然后GigaThread引擎创建并调度这些block到各个SM,其次再到warp(每个warp包含32个threads线程)交给CUDA Core和其他执行单位。在GigaThread引擎重新分配工作时,图形流水线上的各个单元如细分曲面和光栅化之类的单元也会继续工作。
GF100拥有512个CUDA Core,它们属于16个SM单元,每个SM单元包括32个CUDA内核。每个SM是一个高度平行处理器,最多支持在任何规定时间完成对48个warp的处理 。每个CUDA Core是一个统一的处理器核心,执行顶点,像素,几何和kernel函数。一个统一的768KB二级缓存架构负责线程加载、存储和纹理操作。每组SM里四个纹理单元,共享使用12KB一级纹理缓存,并和整个芯片共享768KB二级缓存。每个纹理单元每周期可计算一个纹理寻址、拾取四个纹理采样,并支持DX11新的压缩纹理格式。

Fermi架构GF100核心照片
GF100拥有48个ROP单元,用来执行抗锯齿和原子内存操作。这48个ROP单元被分配为6组,每组8个,每组ROP配备一个内存控制器。内存控制器、L2高速缓存和ROP单元是紧密耦合的,也可以成组屏蔽。所有ROP单元和整个芯片共享768KB二级缓存(GT200里是独享)。
关于运行频率,在每一组SM阵列里,纹理单元、一二级缓存、ROP单元和各个单元的频率也都完全不同于以往。除了ROP单元和二级缓存,几乎其他所有单元的频率都和Shader频率(NVIDIA暂称之为GPC频率)关联在一起:一级缓存和Shader单元本身是全速,纹理单元、光栅引擎、多形体引擎则都是一半。
Fermi颠覆了G80以来的分频模式,曾今我们称固定单元的频率是GPU核心频率,而流处理器频率较高,它的速度是核心的2.15或者2.25倍。从Fermi开始“核心频率”就是流处理器频率(也可以称为GPC频率),而固定单元的频率默认为“核心频率”的一半,未来的超频模式肯定要发生变化了。
由繁化简 GF110/GF100结构组成细说
我们可以这样认为NVIDIA的第一代CUDA机构是从G80开始延伸至GT200,而Fermi将是第二代CUDA架构产品。G80核心的诞生奠定了NVIDIA未来核心架构的主方向,并一直延续至GT200,当然在发展的过程中NVIDIA还是会对核心整体进行优化调整,但总体来说就是累积晶体管增加硬件规格,功能方面并无变化。反观Fermi,核心硬件规格数量相比GT200确实也有大幅增长,但是在产品整体架构上Fermi做了很大改动,可以说是颠覆性改动,它不仅仅是借鉴的以前的成熟架构体系,还调整并在架构上新增功能模块,令Fermi不再简简单单的是图形核心,而是一个复合型功能核心。

NVIDIA Fermi GF100 SM架构
在NVIDIA产品进入DirectX 10的统一架构后,我们看到核心中引入了TPC(Thread Processing Cluster)、SM(Streaming Mulitporcessor)和SP(Streaming Processor)等新概念。例如,G80拥有8个TPC,每个TPC拥有2个SM,每个SM拥有8个SP,这种由繁化简的结构一直延续在NVIDIA的图形产品中。那么Fermi GF100呢?下面笔者用表格进行一个汇总:
| 理 论 性 能 测 试 | ||||
| G80 | G92 | GT200 | GF100 | |
| 每颗GPU含TPC数量 | 8 TPCs | 8 TPCs | 10 TPCs | 4 GPCs |
| 每个TPC含SM数量 | 2 SMs | 2 SMs | 3 SMs | 4 SMs |
| 每个SM含SP数量 | 8 SPs | 8 SPs | 8 SPs | 32 SPs |
通过上面的GF100 SM架构图以及各代顶级芯片的组成我们可以看出,SM矩阵数量在减少(上表中的GPC和TPC),而每个GPC中SM数量和每组SM中SP数量在增加。在这中架构设计理念上GF100虽然是延续了G80的组成设计,但是每个组成模块的数量优化上有了大幅改变。

图片源于Anandtech

Fermi架构GPC架构图
正如其名称所示,所有的GPC都集成了关键的图形处理单元。它包括顶点,几何,光栅,纹理均衡设置和像素处理资源。随着ROP单元功能的不断增强,一个GPC单元可以被看作是一个配置齐全的GPU,而GF100拥有4个这样的核心。
Fermi架构核心 新增强劲神器引擎
Fermi架构核心 新增强劲神器引擎
当然仅是在数量优化上做改变还不能称为第二代CUDA架构,我们在GF100核心架构图和SM架构图上可以看到,相比G80/92和GT200核心架构多了Polymorph Engines和Raster Engines功能模块组。那么它们又是做什么的呢?

全新的Polymorph Engines和Raster Engines
我们可以这样简单的理解,在数据处理流程中的一些功能模块现组成了现在的Polymorph Engines和Raster Engines。其中Polymorph Engines包括Vertex Fetch、Tessllator、Viewport Transform、Attribute Setup和Stream Output,Raster Engines包括Edge Setup、Raterize和Z-Cull。

GF100对比RV870 Tessellation性能
值得一提的是DirectX 11中Tessellation功能是必不可缺的,而Tessellator并不是使用SP来完成,而是采用独立功能模块完成,在这一点上与AMD的做法一致。但不同的是,AMD的Tessellator采用串行计算模式,也就是说核心中只有一个Tessellator功能模块,数据计算从分配到接收Tessellator会成为瓶颈。反观NVIDIA的GF100核心,每组SM拥有一个Polymorph Engines,这也就意味着一个GF100核心拥有16个Tessellator功能模块,在Tessellation多数据并行计算方面GF100遥遥领先RV870。

Polymorph Engines和Raster Engines在GF100中的设计
前文提过每组SM都会标配一个Polymorph Engines,同时每组GPC将独立拥有一个Raster Engines,这样的设计都是增加各种数据计算的并行效果,相比RV870的非Shader计算串行设计要优越很多。
Fermi具备的光栅并行化是一个重要创新。NVIDIA称Fermi GF100是一个全新架构,不但是通用计算方面,游戏方面它也发生了翻天覆地的变化,几乎每一个原有模块都进行了重组:有的砍掉了,有的转移了,有的增强了,还有新增的光栅引擎(Raster Engine)和多形体引擎(PolyMorph Engine)。

光栅引擎(Raster Engine)
光栅引擎严格来说光栅引擎并非全新硬件,只是此前所有光栅化处理硬件单元的组合,以流水线的方式执行边缘/三角形设定(Edge/Triangle Setup)、光栅化(Rasterization)、Z轴压缩(Z-Culling)等操作,每个时钟循环周期处理8个像素。GF100有四个光栅引擎,每组GPC分配一个,整个核心每周期可处理32个像素。

多形体引擎(PolyMorph Engine)
多形体引擎则要负责顶点拾取(Vertex Fetch)、细分曲面(Tessellation)、视口转换(Viewport Transform)、属性设定(Attribute Setup)、流输出(Stream Output)等五个方面的处理工作,DX11中最大的变化之一细分曲面单元(Tessellator)就在这里。Fermi GF100产品中有16个多形体引擎,每个SM一个,或者说每个GPC拥有四个。
凭借多形体PolyMorph引擎,Fermi实现了全球首款可扩展几何学流水线,该流水线在单颗GPU中包含了最多16个Tessellation引擎。这些引擎在DirectX 11最重要的全新图形特性GPU加速Tessellation中能够发挥出革命性的性能。通过将更加细腻的几何图形融入到场景当中,Tessellation让开发人员能够打造出视觉清晰度极高、更加复杂的环境。锯齿边缘平滑了,从而使游戏中所渲染出来的人物能够拥有影院般细腻的画质。
在以前的架构中,固定功能单元只是单一的一条流水线。而在GF100,无论是固定功能单元和可编程操作单元都并行设计,这大大提高图形性能,也解决了GPU长期以来未有重大突破的性能短板。
多形体PolyMorph引擎的出现,是几何流水线近几年间不断演化的重大突破。特别是细分曲面操作,需要的三角形和光栅能力都异常可怕,传统GPU无法应对。多边形引擎的出现大幅度提高了三角形、细分曲面和流输出能力。通过给每个SM搭载属于自己的细分曲面Tessellation硬件单元,并为每个GPC搭载属于自己的光栅化引擎,GF100最终为我们提供了高达8倍于GT200几何性能。
可读写缓存引入GPU 计算能力倍增
可读写缓存引入GPU 计算能力倍增
● 真正缓存概念引入GPU
为了增加计算单元的效能,缓存的概念引入到功能处理器中,例如CPU现在已经拥有L1、L2和L3三个等级缓存,而在GPU中缓存概念还是十分模糊。

GF100引入L2缓存
为了增加GPU的计算能力和计算效率,NVIDIA工程师大胆的将缓存概念引入到GF100中,自然引入缓存势必需要大量晶体管完成,在这点上与CPU道理相同。为了在满足数据计算吞吐率的前提下,NVIDIA工程师为GF100设计了一套实用并灵活的L1和L2。

GT200与GF100缓存设计对比
我们通过上面表格可以看到,在GT200核心中有L1纹理缓存、16KB共享内存和256KB的L2缓存。笔者需要说明的是GT200没有专用L1缓存,只有L1纹理缓存和只读L2缓存,也就是说GT200没有真正意义上的缓存概念。
反观GF100核心,除同样拥有12KB的L1纹理缓存之外,其拥有真正意义的L1缓存和L2可读写缓存。就每组SM而言,每组SM拥有4个纹理单元共享12KB的L1纹理缓存,32个流处理器使用16KB L1缓存搭配48KB共享缓存或48KB L1缓存搭配16KB共享缓存两种组合,最后还有768KB超大L2缓存。
为了增加计算单元的效能,更好地配合计算核心,降低存储器延迟,缓存的概念引入到功能处理器中,例如CPU现在已经拥有L1、L2和L3三个等级缓存,而在GPU中缓存概念还是十分模糊。主要原因是GPU的运算核心数量太多,缓存需求量太大,而另一个方面,在以往的GPU通用计算程序中,确实很少有用到缓存,特别是可读写的真正意义上的缓存。

CPU和GPU功能性单元对比
为了增加GPU的计算能力和计算效率,NVIDIA工程师大胆的将缓存概念引入到GF100中,自然引入缓存势必需要大量晶体管完成,在这点上与CPU道理相同。这样的选择要承担很大风险,但是面向应用设计的GPU必须进行改进,也必须直面问题而不能回避。为了在满足数据计算吞吐率的前提下,NVIDIA工程师为GF100设计了一套实用灵活的L1和L2。
通过了解不同的成千上万的应用程序,NVIDIA工程师发现shared memory可以解决一部分程序的需求,但是不能解决所有的问题。一些应用程序天然需要shared memory,有些应用程序则需要缓存cache,有的既需要shared memory也需要cache。优化的内存设计可以既提供shared memory也提供cache,可以让程序员根据自己的需求来做选择。Fermi架构通过变化存储器的资源配置,可以同时支持这两种需求。

Fermi架构可配置缓存结构
GF100的每一个SM中拥有64KB的可配置片上缓存,可以设置为48KB共享缓存加16KB L1缓存,也可以设置为16KB共享缓存加48KB L1缓存。在之前的GT200核心中,并没有L1缓存的设计。L1缓存可以用于处理寄存器溢出、堆栈操作和全局LD/ST。过去,GPU的寄存器如果发生溢出,会大幅度增加存取时延。
有了L1缓存以后,即使临时寄存器使用量增加,程序的性能表现也不至于大起大落,双精度等运算的衰减控制也将更为优秀。对于那些无法预知数据地址的算法,例如物理计算、光线追踪都可以从GF100的专用L1缓存设计中显著获益。共享缓存的设计则有利于多线程间数据重用,让程序把共享缓存当成缓存来使用,由软件负责实现数据的读写和一致性管理。而对那些没有使用共享缓存的应用程序来说,也可以直接从L1缓存中受益,显著缩减运行CUDA程序的时间。

GT200和GF100架构缓存构成形式与容量对比
Fermi有768KB的统一的L2缓存,可以支持所有的存取和纹理操作。L2缓存和所有的SM都相通。L2提供有效和高速的数据支持。有些算法不能在运行前就确定下来,像一些物理问题,光线跟踪,稀疏矩阵乘法,尤其需要缓存的支持。过滤器和转换器需要所有的SM都去读取相同数据的时候,缓存一样会有很大的帮助。
而Fermi的对手代号R800的HD5870所具备的cache是不可随便调用的,HD5870的缓存实际上是传统的Texture cache,只不过现在可以用来临时释放结果做LDS(Local Data Share),不可编程,不可操作,不可写,只读。所以R800现在是16KB LDS+16KB cache,也就是说专用LDS只有16KB。
这里顺便提及Fermi首次在GPU中引入全局ECC的作用。Fermi是第一款支持内存错误检查和修复(ECC)的GPU架构。在使用GPU做大数据量的处理和高性能计算的时候,ECC是有大量的需求。在医疗图像处理和大型集群中,ECC是最有用的特性。
正常情况下的内存位的存储错误,都会引起软件的错误。ECC就是在上述错误没有多系统造成影响的情况下,用来检查和纠正这样的错误。由于这样的错误会根据系统的增大线性的增加,ECC就成为大型集群中必不可少的需求。
Fermi架构GPU的寄存器,共享内存,L1缓存,L2缓存和DRAM内存都受到ECC保护,这样的设计部只是为了高性能的GPU应用,也是为了增加系统的可靠性,这是大规模部署Tesla等高端通用计算产品的前提。但是ECC技术是在原来的数据位上外加位来实现的,所以支持ECC技术的Fermi实现各种存储的代价,都要大于普通GPU。当然我们也找到另外一种说法称FermiDRAM ECC实现机制和传统CPU每8-bit增加一个位元的方式不一样,是一种专利方式。
Fermi架构针对GPU通用计算优化
Fermi架构针对GPU通用计算优化
● 强大的线程调度能力
关于线程的调度问题,我们首先需要了解一些G80以来CUDA架构的线程关系。
线程结构:CUDA将计算任务映射为大量的可以并行执行的线程,并且硬件动态调度和执行这些线程。Kernel以线程网格(Grid)的形式组织,每个线程网格由若干个线程块(block)组成,每个线程块又由若干个线程(thread)组成。实质上,kernel是以block为单位执行的,CUDA引入Grid只是用来表示一系列可以被并行执行的block的集合。各block是并行执行的,block间无法通信,也没有执行顺序。目前一个kernel函数中有一个grid,而未来支持DX11的硬件采用了MIMD(多指令多数据)架构,允许在一个kernel中存在多个不同的grid。

线程、线程块和执行内核的关系
Block:CUDA中的kernel函数实质上是以block为单位执行的,同一block中的线程需要共享数据,因此它们必须在同一个SM中发射,而block中的每一个线程(thread)则被发射到一个SP上执行。一个block必须被分配到一个SM中,但是一个SM中同一时刻可以有多个活动线程块(active block)在等待执行,即在一个SM中可以同时存在多个block的上下文。当一个block进行同步或者访问显存等高延迟操作时,另一个block就可以“趁虚而入”,占用GPU资源,最大限度利用SM的运算能力。
arp:在实际运行中,block会被分割为更小的线程束,这就是warp。线程束的大小由硬件的计算能力版本决定。在目前所有的NVIDIA GPU中,一个线程束由连续的32个线程组成。warp中的线程只与thread ID有关,而与block的维度和每一维的尺度没有关系,这种分割方式是由硬件决定的。以GT200的角度来解释,warp中包含32条线程是因为每发射一条warp指令,SM中的8个SP会将这条指令执行4遍。在硬件中实际运行程序时,warp才是真正的执行单位。虽然warp是一个由硬件决定的概念,在抽象的CUDA编程模型中并不存在,但是其影响力绝对不容忽略。
●SM单元的双warp调度能力
Fermi的每一个SM都有两个指令发送单元,可以同时让两个warp相互独立的并发运行。Fermi的Dual warp调度机制可以同时并发调度两个warp的一条指令分别在16个一组的CUDA core上进行计算,或者在16个存/取单元运行,或者4个SFU上运行。Fermi的调度器并不需要在指令流之间进行附属检查。利用如此优美的双发射调度机制,使得Fermi可以让硬件的计算能力达到极致。

Fermi架构的Warp运行关系
在Fermi架构中,非常多的指令可以进行双发射,例如两条整数运算指令,两条浮点数运行指令,或者混合的整数,浮点,存取,和SFU特殊处理指令都可以被并发执行。单精度和双精度的指令一样可以并发执行。
●并行指令更自由
NV不断充实周边资源,使用更激进的架构,而AMD不断扩大流处理器规模,都是为了更好的隐藏延迟。GT200架构已经可以控制SMIT活用跳转来在实现线程在不同的SM单元之间进行跳跃。命令单元为multi-thread模式,能够执行Out-of-Order指令,而当处理warp命令流时则是In-Order,而根据NV架构设计师John Nickolls的介绍,GT200架构实际warp中的线程也能够支持Out-of-Order。
Fermi在每个SM前端都有两个Warp调度器和两个独立分配单元,和SM其它部分完全独立,均可在一个时钟循环里选择发送一半Warp,而且这些线程可以来自不同的Warp。分配单元和执行硬件之间有一个完整的交叉开关(Crossbar),每个单元都可以像SM内的任何单元分配线程(不过存在一些限制)。
作为运算单元的CUDA核心在Fermi的SM每个单元中共2个组,每组16个,SFU有4组,载入/存储单元16个。这4个小组能够各自并行执行不同的Warp不同的指令。由于CUDA核心是16个一组,16线程并列会让物理vector变长。因此2个周期能够以32线程构成的单Warp的一个指令。载入/存储单元也同样如此。SFU因为是4线程并列,因此是以8周期执行1个warp。这样指令单元本身增加到了2个,各个指令单元能够每个周期发出2条指令。可以说Fermi实现的并行化指令自由度更高。
●GigaThread线程调度优化
Fermi架构的另一个重要特性,就是它的双层分布式调度机制。在片上的层面(SPA Streaming Processor Array,流式处理器矩阵级别),全局的分布式线程调度引擎(global work distribution engine)分发block到每一个SM上,在SM层面,每一个warp分布式调度引擎按照32个线程为一个warp执行。
Fermi实现了SM级别的双发射,意味着SPMD(单线程多任务)的实现。从并行kernel下探到最底层,实际上就是靠的SM级别的双发射。SM级别的SPMD上升到GPU核心级别,Fermi就是MPMD(多线程多任务)。这种设计已经越来越像CPU,而且随着GPU的发展,每走一步,就多像一份。

Fermi实现了SM单元级别的双发射
第一代GigaThread线程调度引擎,在G80架构中实现了12288个线程的实时的调度管理。Fermi架构不只是增强了原有的机制,而且引进了更快的context上下文交换机制,并行kernel执行机制,增强了线程block的调度能力。Fermi的这项能力相对于上一代GPU提高了10倍。
同时像CPU一样,GPU也可以利用context上下文交换机制来管理多任务的切换,每一个任务都可以用分时的方式利用处理器的计算资源。Fermi的运算流水线经过优化设计,把context上下文的切换时间减少到了10~20毫秒,极大的优化了上一代的GPU架构。不只是性能的提高,这个设计可以让开发者创建更快的kernel-to-kernel应用程序,例如让程序在图形和PhysX上的应用,图形与物理效果处理之间的运算也将受益于更快的context上下文交换机制。
● 并行执行内核Concurrent Kernel Execution

并行执行内核让资源利用更充分,计算速度更快
Fermi支持kernel并发运行,同一应用程序的不同kernel可以同时运行在GPU上。Kernel并发机制可以让应用还曾向执行更多的kernel来发挥GPU的能力。例如,PhysX应用程序需要计算流体和固体,如果是串行执行,只能利用一半的线程处理器。Fermi的架构可以让同一个CUDA context的kernel都同时运行在同一个GPU上,这样可以更有效的利用GPU的资源。不同应用程序context的kernel函数也可以通过更快速的context切换,更快地运行在GPU上。
传承尊贵/豪华 GTX580全景赏析
传承尊贵/豪华 GTX580全景赏析
GeForce GTX 580作为NVIDIA新一代的旗舰产品,自然在产品设计、用料及外观上毫不吝啬,这也是NVIDIA在高端产品中一贯作风。虽然GeForce GTX 480在产品发热量和功耗上让人诟病,但是其实际性能以及用料上却没有丝毫缩水。例如外露的5热管、例如核心裸露式核心散热片等等,纯铜+镀镍的工艺让我记忆犹新,那么GeForce GTX 580又会使用哪些更加豪华的设计呢?
GeForce GTX 580
GeForce GTX 580的外观并没有让笔者感到超越GeForce GTX 480的豪华,反而更像是GeForce GTX 470的外观设计,不见了裸露的热管和铜质散热片,整齐划一的导风罩100%覆盖了PCB。


GeForce GTX 580正反特写
虽然GF100核心和GF110核心有着深度的相似,但是NVIDIA并没有直接使用GeForce GTX 480的PCB,而是采用了优化、改良而来的PCB,最明显的差别就是在PCB上没有为散热器开槽入风口,我们可以从显卡背面特写看到。

GeForce GTX 580

GeForce GTX 580斜上角度特写

GeForce GTX 580顶部特写

GeForce GTX 580头部特写
公版GeForce GTX 580采用双槽设计,这样的设计能够在满足高端产品散热的前提下保证主板扩展槽的利用率。同时我们能够看到,整个散热器的入风口仅有离心式风扇的正上方,而出风口为显卡顶部末端和后档板处,这样的设计不仅能够为显卡提供独立散热风道,同时符合机箱风道设计,协助整机散热。

GeForce GTX 580风扇及入风口特写
无论NVIDIA还是AMD,二者的中高端产品无一例外的采用了离心式风扇的设计,这样设计的好处是进风量大,能够吹透例如GeForce GTX 580这样10.5吋长PCB所覆盖的散热模组。不过值得一提的是,GeForce GTX 580相比GeForce GTX 480使用了直径更大的风扇,提供更强但较安静的效果。
也许所有读者已经能够感觉到,GeForce GTX 580的散热器设计仅从外观判断要比GeForce GTX 480简约,那是因为GeForce GTX 580功耗、发热量更新,还是散热模组内藏高效散热玄机?这个谜团我们会在稍后章节揭秘。

接口采用DVI-I *2 + Mini HDMI
显卡的视频信号输出接口采用DVI *2搭配Mini HDMI的组合,这与目前GeForce 4系列中高端产品设计一样。通过附件中配送的DVI to D-Sub转换器,能够满足绝大部分用户的视频显示终端使用。同时借助GF110核心在高清解码能力,能够轻松应对时下主流Full HD高码流视频,让用户体验终极3D性能和强劲2D视觉感受。
完全拆解GTX580 PCB零距离接触
完全拆解GTX580 PCB零距离接触
前文我们曾经提及过,虽然GF110和GF100核心有着惊人的相似度,但是GeForce GTX 580并没有采用“拿来主义”的照搬GeForce GTX 480 PCB,而是在GeForce GTX 480 PCB基础上二次开发而来,最明显的特征就是PCB上不再有散热器如风预留口。

GeForce GTX 580 PCB特写
公版GeForce GTX 580 PCB为10.5吋长,这是目前消费级单芯旗舰产品的极限长度,无论是AMD还是NVIDIA。PCB的设计思路是整套核心、显存供电及外接供电模组设计在PCB右侧,核心位于PCB中心偏左,12颗显存呈“冂”字形以3+5+4的数量围绕在GF110周围。


供电PCB正反特写
显卡的整套供电系统采用核心、显存6+2相设计,每相供电模组军采用屏蔽式铁素电感、八爪鱼式Mosfet还有HI-C聚合物电容构成,当然为了满足244瓦的TDP设计还标配了6pin+8pin外接供电,理论上能够提供300瓦供电需求。

显存供电特写
显存供电为2相设计,无论电感、电容及Mosfet均采用了优质的贴片材料。

核心PWM芯片CHiL CHL8266
核心6相供电采用了CHiL提供的CHL8266解决方案,这可PWM芯片最高支持6相数字供电,同时这可芯片能够预设多种运行模式,例如显卡待机、满载、视频播放、3D计算等,同时根据核心负载率调整供电使用模组数,这样设计的好处就是能够有效根据不同应用施以不同功耗对应,做到节能的目的。值得一提的事,CHL8266芯片最大可支持200A电流和2V电压,最高可支持400瓦显卡稳定运行。

显存PWM芯片茂达APW7088
由于CHiL的CHL8266被6相核心供电所全部占用,所以两相显存供电需求另一颗PWM芯片支持。GeForce GTX 580显存供电所使用的显存PWM芯片为茂达APW7088,该芯片最多支持2相供电模组管理。值得一提的事APW7088 PWM芯片,采用了全新的无卤素封装工艺符合RoHS环保标准。

Mosfet驱动芯片为CHiL CHL8510和低功耗
核心6相供电每相标配1颗屏蔽式铁素电感、1个HI-C聚合物电容、3个Mosfet,还有一颗独立Mosfet驱动IC,GeForce GTX 580所采用的驱动IC为CHiL的CHL8510芯片。

HI-C电容(高导电聚合物电容)
细心的用户可能会发现,GeForce GTX 580的核心、显存供电没有采用一颗电解电容或者固态电容,而是全部采用了HI-C高导电聚合物电容。不过在PCB正面的核心供电位置,还是预留的普通电容焊位。
不过笔者需要说明的是,GeForce GTX 480在供电用料上明显优于GeForce GTX 580,因为每相核心供电不仅搭配了与GeForce GTX 580相同的电气件,还补全了电容焊位。但GeFoce GTX 580这样的设计是否意味着其功耗低,无需高成本供电用料。

6pin+8pin外接供电设计
显卡外接供电采用6pin+8pin的组合,同时搭配PCI-Exrepss的供电,最高提供300瓦,相比244瓦的TDP而言绰绰有余。

6+2相供电设计


全新的电源管理系统
GeForce GTX 580的供电模组PCB旁边没有了类似GeForce GTX 480的入风口设计,在这片PCB区域上,NVIDIA为其增加了全新电源监控模组。
这个全新的电源管理模组能够实时监控每相供电模组的电流和12V电压,在不同压力负载下动态调整供电模组调配,实现节能的目的。
NV旗舰不用热管 引入均热板技术
NV旗舰不用热管 引入均热板技术
GeForce GTX 480的功耗及发热量相比无论用过还是没用过的网友,都深知它的“实力”。而与其一奶同胞的GF110核心是否还会延续GF100核心的高功耗及高发热量呢?
俗话说“兵来将挡水来土掩”,芯片的高功耗只能在设计及制造端解决,但是高发热量我们可以在散热器端进行改良而降低,相比高功耗控制来说更加容易些。那么GeForce GTX 580使用了怎样的散热器呢?


公版散热器正反面
仅从GeForce GTX 580的散热器正反特写,也许我们还是无法体会到其有何特殊之处,不过下面的拆解将会告知大家GeForce GTX 580散热器的过人之处。不过通过上图我们还是能够了解到,显卡采用了一体式散热设计,散热器骨架同时还肩负起显存及其他电气件的吸热底工作,同时有专门的核心散热器为GPU散热。

核心散热器采用均热板设计
GeForce GTX 580采用了无热管设计核心散热模组,转而使用均热板技术。该技术与热管的原理类似,均为利用真空/高压/貌似作用导热。均热板是一个内壁具微结构的真空墙体,当热由热源传导至蒸发区时,腔体里的冷却液会在低真空环境中开始产生冷却液气化现象,此时吸热区变回产生冷凝现象,最终由与均热板连接的散热器将热量散发出去。
值得一提的是,均热板在热传导效率、效能上远大于热管,更不说弯曲后的热管。




均热板4边长度
均热板的尺寸如上,由于为了满足散热器设计需求,均热板并没有采用正规的长方形表面,具体尺寸如上。


核心散热模组正反特写


铝鳍及均热板特写
核心散热模组由精细的扣Fin工艺铝鳍和均热板构成,而均热板上的吸热底采用了抛光工艺,增加吸热底与核心的接触面积。


显卡导风罩正反特写


散热器一体式骨架


散热器离心式风扇
显卡散热器的其他组成部分还有导风罩、骨架和离心式风扇。

GeForce GTX 580专用一体式散热器骨架


无法通用在GeForce GTX 480产品中
纵然GF110和GF100核心十分相似、纵然GeForce GTX 580和GeForce GTX 480的PCB也十分相似,但是二者的散热器却不能通用,我们可以看到当GeForce GTX 580的散热器装在GeFoce GTX 480上时,被显存供电模组中的固态电容挡住。
大家来找茬 GTX580/GTX480外观对比
大家来找茬 GTX580与GTX480之外观对比
本环节将着重展示GeForce GTX 580和GeForce GTX 480之间的不同之处及产品对比展示。从多角度的特写,让用户了解GeForce GTX 580并非简单的使用满规格GF100核心而已,而是使用了全新核心、全新PCB、全新散热器组成的全新产品。

GeForce GTX 580和GeForce GTX 480正面特写

GeForce GTX 580和GeForce GTX 480风扇端特写
从外观上来说二者形状较为相似,不过导风罩材料和一些细节差异较大,一眼就能帮我们识别出谁是GeForce GTX 580,谁是GeForce GTX 480。

GeForce GTX 580和GeForce GTX 480顶部特写
二者均采用10.5吋PCB长度和双槽设计,同时在产品顶部设计上除了GeForce GTX 480裸露的热管之外,出风口、外接供电均相同。


GeForce GTX 580和GeForce GTX 480多卡模式下进风口设计
GeForce GTX 580在多卡互联散热上对导风罩做了小优化,我们可以看到左图中下面的GeForce GTX 580和上面的卡之间入风口较大,反观右图中下面的GeForce GTX 480入风口位置较小,不利于多卡互联散热。

GeForce GTX 580"体重"

GeForce GTX 480"体重"
下面对GeForce GTX 480和GeForce GTX 580进行一个重量对比,我们发现由于二者重量差别主要集中在散热器上,采用原始热管搭配散热板设计的GeForce GTX 480重量为0.933千克,而经过减负的GeForce GTX 580仅为0.884千克。
大家来找茬 GTX580/GTX480之PCB对比
大家来找茬 GTX580与GTX480之PCB对比
对比完NVIDIA两代旗舰产品外观之后,接下来我们详细对比两款产品的PCB之间区别。

GeForce GTX 580和GeForce GTX 480 PCB正面特写

GeForce GTX 580和GeForce GTX 480 背面特写
乍一看,GeForce GTX 580和GeForce GTX 480二者PCB之间的区别主要集中在PCB入风口和供电模组电容上。

GeForce GTX 580和GeForce GTX 480供电模组特写

GeForce GTX 580和GeForce GTX 480 PCB背面顶端特写


GeForce GTX 580和GeForce GTX 480核心背部用料特写
在核心背部PCB的电气件用料上,GeForce GTX 580增设了4可HI-C电容,增加核心滤波效果,从而减少高频、高规格带来的负面影响。

GeForce GTX 580和GeForce GTX 480 辅助用料对比

GeForce GTX 580和GeForce GTX 480 供电用料对比

GeForce GTX 580和GeForce GTX 480 辅助用料对比

GeForce GTX 580和GeForce GTX 480 PCB版本号
GeForce GTX 580使用的公版PCB型号为P1261,而公版GeForce GTX 480的公版PCB型号为P1022。
GTX580测试平台及测试项目简介
● 测试系统硬件环境
| 测 试 平 台 硬 件 | |
| 中央处理器 | Intel Core i7-975 Extreme Edition |
| 散热器 | Thermalright Ultra-120 eXtreme |
| 内存模组 | Apacer PC3-12800 猎豹套装 2GB*2 |
| (SPD:1600 8-8-8-24-2T) | |
| 主板 | ASUS P6T Deluxe |
| (Intel X58 + ICH10R Chipset) | |
| 显示卡 | |
| AMD 产 品 | |
| Radeon HD 6870 | |
| (Barts / 1024MB / 核心:900MHz / Shader:900Mhz / 显存:4200 Mhz) | |
| Radeon HD 6850 | |
| (Barts / 1024MB / 核心:775MHz / Shader:775Mhz / 显存:4000 Mhz) | |
| Radeon HD 5870 | |
| (Cypress / 1024MB / 核心:850MHz / Shader:850Mhz / 显存:4800 Mhz) | |
| Radeon HD 5850 | |
| (Cypress / 1024MB / 核心:725MHz / Shader:725Mhz / 显存:4000 Mhz) | |
| Radeon HD 5830 | |
| (Cypress / 1024MB / 核心:800MHz / Shader:800Mhz / 显存:40800 Mhz) | |
| NVIDIA 产 品 | |
| GeForce GTX 580 1536MB | |
| (GF110 / 1536MB / 核心:772MHz / Shader:1544Mhz / 显存:4008Mhz) | |
| GeForce GTX 480 1536MB | |
| (GF100 / 1280MB / 核心:700MHz / Shader:1401Mhz / 显存:3696 Mhz) | |
| GeForce GTX 470 1280MB | |
| (GF100 / 1280MB / 核心:607MHz / Shader:1215Mhz / 显存:3348 Mhz) | |
| GeForce GTX 465 1024MB | |
| (GF100 / 1280MB / 核心:607MHz / Shader:1215Mhz / 显存:3206 Mhz) | |
| GeForce GTX 460 1024MB | |
| (GF104 / 1024MB / 核心:675MHz / Shader:1350Mhz / 显存:3600 Mhz) | |
| GeForce GTX 460 768MB | |
| (GF104 / 768MB / 核心:675MHz / Shader:1350Mhz / 显存:3600 Mhz) | |
| 硬盘 | Hitachi 1T |
| (1TB / 7200RPM / 16M | |
| 电源供应器 | AcBel R8 ATX-700CA-AB8FB |
| (ATX12V 2.0 / 700W) | |
| 显示器 | DELL UltraSharp 3008WFP |
| (30英寸LCD / 2560*1600分辨率) | |

Apacer猎豹6GB DDR3-1600套装

AcBel R8 ATX-700CA-AB8FB

Thermalright Ultra-120 eXtreme
我们的硬件评测使用的内存模组由宇瞻(Apacer)中国区总代理佳明国际提供,电源供应器、CPU散热器由华硕(ASUS)玩家国度官方店、利民(Thermalright)的北京总代理,COOLIFE玩家国度俱乐部提供。
● 测试系统的软件环境
| 操 作 系 统 及 驱 动 | |
| 操作系统 | |
| Microsoft Windows 7 Ultimate RTM | |
| (中文版 / 版本号7600) | |
| 主板芯片组 驱动 |
Intel Chipset Device Software for Win7 |
| (WHQL / 版本号 9.1.1.1125) | |
| 显卡驱动 | |
| AMD Catalyst for Win7 | |
| (WHQL / 版本号 10.10) | |
| NVIDIA Forceware for Win7 | |
| (WHQL / 版本号 260.99) | |
| NVIDIA Forceware for GTX580 | |
| (Beta / 版本号 262.99) | |
|
|
2560*1600_32bit 60Hz |
| 测 试 平 台 软 件 | ||
| 3D合成 测试软件 |
3Dmark 06 | |
| Futuremark / 版本号1.2 | ||
| 3Dmark Vantage | ||
| Futuremark / 版本号1.2 | ||
| 3D游戏 测试项目 | ||
| DirectX 9游戏 | ||
| Star Craft II | ||
| Blizzard / 版本号 1.0 | ||
| Street Fighter IV | ||
| Comcap / 版本号1.0 | ||
| DirectX 10游戏 | Company of Heroes | |
| Relic / 版本号1.7.1 | ||
| Crysis | ||
| Crytek / 版本号1.2.1 | ||
| DirectX 11游戏 | Alien vs. Predator | |
| SEGA / 版本号 1.0 | ||
| Battlefield:Bad Company 2 | ||
| EA / 版本号 1.0 | ||
| Colin McRae DiRT 2 | ||
| Codemasters / 版本号 1.01 | ||
| Lost Planet 2 | ||
| Copcom / 版本号 1.0 | ||
| Metro 2033 | ||
| 4A Game / 版本号 1.0 | ||
| S.T.A.L.K.E.R.:Call of Pripyat | ||
| Koch / 版本号 1.0 | ||
| Tom Clancy's HAWX 2 Benchmark | ||
| Ubi / 版本号 Benchmark 1.0 | ||
| Tessellation测试 | ||
| Heaven Benchmark 2.1 | ||
| UNIGINE / 版本号 2.1 | ||
| Sub11-Microsoft SDK | ||
| Microsoft / 版本号 Demo | ||
| PhysX游戏 | Batman | |
| Eidos / 版本号 1.1 | ||
| GPU通用计算 | Media Coder NT CUDA加速版 | |
| 上海瀚智信息技术有限公司 / 版本号 | ||
| 辅助测试软件 | Fraps | |
| beepa / 版本号 3.2.3 | ||
各类合成测试软件和直接测速软件都用得分来衡量性能,数值越高越好,以时间计算的几款测试软件则是用时越少越好。
理论性能测试-3Dmark 06
● DX9理论性能测试:3DMark 06
3Dmark 06作为上一代3DMark系列巅峰之作,所有测试都需要支持SM3.0的DirectX 9硬件,并且支持HDR特性,这款软件的最终得分里CPU性能占有不小的权重,因此它更适宜分析整个系统的3D加速能力。


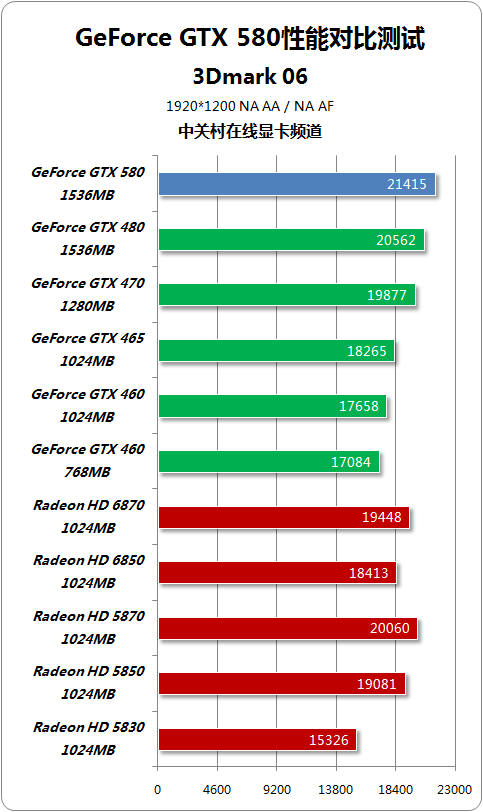




在3Dmark 06测试中,低画质、低负载测试项目下各款产品的性能差距较小,随着画质的提升GeForce GTX 580性能有时愈加明显,在最高画质2560*1600 8X AA / 16X AF下能够领先GeForce GTX 480多达14%。
理论性能测试-3Dmark Vantage
● DX10理论性能测试:3Dmark Vantage
3DmarkVantage是Futuremark最新推出的一款显卡3D性能测试,该款软件仅支持DirectX 10系统及DirectX 10显卡。测试成绩主要由两个显卡测试和两个CPU测试构成,整个测试软件各家偏重整机性能。




在3Dmark Vantage测试中,由于软件对PhysX-GPU支持,所以NVIDIA产品在总成绩上占有优势,不过我们可以直接对比每款产品在每个画质下的GPU_Test下成绩。
而在这个环节的GPU_Test中,GeForce GTX 580相比自家和竞争对手的原顶级单芯产品,最大均有30%以上的性能领先优势。
DX9.0c游戏-星际争霸2
● StarCraft II
星际争霸2(StarCraft II)是著名即时战略游戏《星际争霸》的续篇, 由2007年5月19日在韩国首尔开幕的暴雪全球邀请赛宣布。目前以Windows XP、Windows Vista和Mac OS X为支援平台。这款游戏的开发在2003年《魔兽争霸III:冰封王座》出版后就开始。至今,公测版免费试玩。

>>游戏类型:DirectX9即时战略游戏
>>测试方式:游戏录像回放,内容为3D实时运算的对战录像
>>画质设定:全部最高
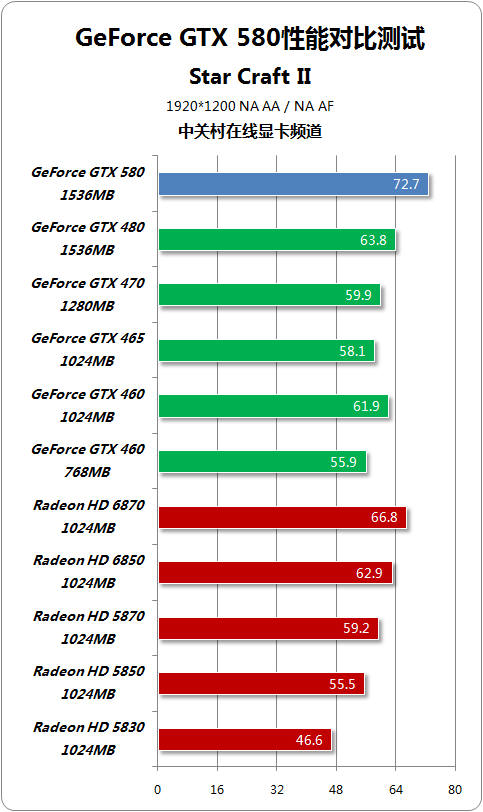



在《星际争霸2》游戏测试中,该款游戏CPU和GPU的要求较为平均,所以我们能够看到当在低画质项目中GeForce GTX 580优势并不明显,即使千元产品也能与其保持相近的成绩。不过在2560*1600 4X AA / 16X AF画质下,各卡实际性能原形毕露基于GF110和GF100的产品优势非常明显,尤其是GeForce GTX 580。
DX9.0c游戏-街头霸王4
● Street Fighter IV
由CAPCOM负责开发的格斗游戏《街头霸王4》(Street Fighter 4)早已在电视游戏机上发售,经过漫长的等待,街霸迷们终于盼到了PC版的发布。本作不仅继承了TV Game版的所有特色,还增加更多诸如画面风格等特色。

>>游戏类型:DirectX9格斗类游戏
>>测试方式:游戏自带性能测试工具,内容为3D实时运算的战斗回放
>>画质设定:全部最高




对于这款属于“游戏之道”计划中的《街头霸王IV》中,NVIDIA产品的优势固然明显,不过在所有测试项目中,虽然AMD产品表现不济NVIDIA产品,不过此次所有测试产品均能保证游戏运行在最高画质下且绝对流畅运行。
DX10游戏-英雄连之前线
● Company of Heroes
Company of Heroes(英雄连)是一款即时战略类游戏。二战是几年来长盛不衰的3D游戏题材,Company of Heroes就是从101空降师诺曼底登陆后在欧洲战场血战题材入手的最新战略游戏,不过其自带测试并非针对即时战略的实际场景,反而更像第一人称视角游戏。

>>游戏类型:DirectX10 即时战略游戏
>>测试方式:游戏自带性能测试工具,内容为3D实时运算的剧情过场回放
>>画质设定:全部最高




在《英雄连》游戏测试中,由于游戏的AI还需要CPU来完成,所以GeForce GTX 580在1920*1200两个画质下的成绩十分接近,此时平台短板为CPU,GPU性能过剩。不过随着画质的提升GeForce GTX 580真实性能逐渐表现,同时以较大幅度领先其他对比产品。
DX10游戏-孤岛危机
● Crysis
多次跳票、万众期待的DirectX 10游戏大作Crysis,把目前PC 3D娱乐的视觉体验发挥到极致的游戏,大量使用DirectX 10的硬件功能,对显卡的负载也提升至空前水平。

>>游戏类型:DirectX10 第一人称视角射击游戏
>>测试方式:游戏自带GPU性能测试工具,为3D实时运算的飞行过场回放
>>画质设定:全部最高




当年的游戏杀手《Crysis》逐渐被新一代顶级产品所征服,GeForce GTX 580就是这样一款产品,在主流最高分辨率下的高画质中, 能够轻松胜任,同时领先本家GeForce GTX 480轻松达到20%幅度以上。
DX11游戏-异形大战铁血战士
● Aliens vs. Predator
由Rebellion开发、世嘉发行的科幻射击游戏《异形VS铁血战士》(Aliens vs. Predator)现已确定发售日期。根据世嘉的《异形VS铁血战士》官方网页的信息,本作将于2010年2月19日上市,对应PC、PS3和Xbox 360平台。这部根据电影改编的游戏也同样存在着三方势力,一方是人类海军陆战队,一方是异形,还有一方是铁血战士,游戏中玩家可以选择的是海军陆战队或者是铁血战士甚至是异形。本作提供单人模式和多人模式。

>>游戏类型:DirectX11第一人称射击类游戏
>>测试方式:沿同一固定路线跑完3次取平均值,Fraps计速
>>画质设定:全部最高




《异形大战铁血战士》游戏不得不说这是一款针对A卡优化的游戏,即使GeForce GTX 480也无法在高画质下战胜A卡高端,不过GeForce GTX 580的出现彻底改变了这一现象。不过对于用户而言,目前A/N千元以上中高端显卡都能满足游戏在高画质下的流畅运行。
DX11游戏-战地之叛逆连队2
● Battlefield: Bad Company 2
《战地:叛逆连队2 (Battlefield: Bad Company 2) 》是EA DICE研发的第9款“战地”系列作品。它是2008年上市的同系列的游戏战地:叛逆连队的续作。两在单人游戏剧情上亦有很多交叉点。游戏仍然沿用前作的寒霜引擎,并有所改进。除了完善了代码的优化,本作在破坏效果上也有所加强,可破坏的物件由92%上升到99%。前作里不能破坏的小物件以及建筑物框架,在本作中也可以被破坏。

>>游戏类型:DirectX11第一人称射击类游戏
>>测试方式:沿同一固定路线跑完3次取平均值,Fraps计速
>>画质设定:全部最高




在《战地:叛逆连队2》游戏测试中,GeForce 4系列和Radeon HD 6000系列互有胜负,不过GeForce GTX 580的出现可谓一统江湖。
DX11游戏-科林麦克雷之尘埃2
● Colin McRae:DiRT2
《科林麦克雷:尘埃》本身是一款为纪念去世的英国拉力赛车手科林.麦克雷(Colin McRae)而制作的游戏,因此在游戏过程中不难见到许多麦克雷过往的身影,距前作将近二年多之久的《科林麦克雷:尘埃2》于2009月12月11日正式发售。值得一提的是,这款游戏不仅拥有很高的可玩性,同时还是率先支持DirectX 11 API的游戏,一经上市就得到广大游戏爱好者争相追捧。

>>游戏类型:DirectX 11竞速类游戏
>>测试方式:
>>画质设定:全部最高




《科林麦克雷:尘埃2》游戏测试中,NVIDIA高端产品的性能优势较为明显,GeForce GTX 580和GeForce GTX 480遥遥领先,同时前者还领先后者最高多达40%以上。
DX11游戏-失落星球2
● Lost Planet 2
《失落的星球2》背景设在原来第一季的十年后。气候变化融化冰雪覆盖的大陆,创造了新的环境,如丛林。在EDN-3rd的改变下,10年过去了。地球发生了重大改变,冰川已经融化,热带丛林,沙漠冷酷无情。玩家将进入新的环境,与雪贼战斗,以抓住不断变化的地球控制权。玩家将控制他们的英雄跨越6个相互关联的事件,创造一个真正独特的互动体验。有了这个概念,玩家将会有机会从不同的发展角度来动态的改变故事情节。

>>游戏类型:DirectX11 第一人称视角射击游戏
>>
>>画质设定:全部最高




《失落星球2》这款游戏对Tessellation性能十分依赖,我们可以通过上面的数据了解到,只有1个Tesselltaion的所有A卡性能表现一般且较为平均。反观NVIDIA产品,不同定位产品设定了不同的Tessellation数量,其中GeForceGTX 580最多为16个,所以性能表现最强。
DX11游戏-地铁2033
● Metro 2033
本作题材基于俄罗斯最畅销小说Dmitry Glukhovsky。由乌克兰4A游戏工作室开发,采用4A游戏引擎,而且PC版支持nvidia的PhysX物理特效。 2013年,世界被一次灾难性事件毁灭,几乎所有的人类都被消灭,而且地面已经被污染无法生存,极少数幸存者存活在莫斯科的深度地下避难所里,人类文明进入了新的黑暗时代。直至2033年,整整一代人出生并在地下成长,他们长期被困在“地铁站”的城市。

>>游戏类型:DirectX11 第一人称视角射击游戏
>>
>>画质设定:全部最高


《地铁2033》可以说是现阶段对显卡要求最高的DirectX 11游戏,从实际测试中我们也能看出在1920*1200分辨率下GeForce GTX 580也仅能勉强保持流畅运行标准。不过就性能而言,依然是GeForce GTX 580领跑所有产品。
DX11游戏-潜行者之普利皮亚召唤
● S.T.A.L.K.E.R.: Call of Prypiat
作为第二款支持DX11技术的游戏,《S.T.A.L.K.E.R.: Call of Prypiat》(潜行者:普里皮亚季的召唤)已于2009年11月中在德国、奥地利、瑞士三个国家先行上市销售,明年第一季度再登陆北美、英国和其他欧洲国家。该游戏此番发行了两个版本,一是普通的标准版,然后就是限量收藏版了,采用金属包装盒里,里边除了游戏本身还有一张A3地图,以及相关主题的打火机、徽章、头巾等小礼物。

>>游戏类型:DirectX11 第一人称视角射击游戏
>>
>>画质设定:全部最高




《潜行者:普利皮亚召唤》这款游戏多核CPU支持不佳,不过对显卡要求还是较高,千元级别产品已经无法满足高分辨率下的流畅运行,不过GeForce GTX 580表现十分出色,大幅领先GeForce GTX 480。
DX11游戏-汤姆克兰西之鹰击长空2
● Tom Clancy's HAWX 2
《鹰击长空2》是一款结合了拟真与空战要素而成的模拟飞行游戏,玩家可驾驶多种高性能战机,在高空中进行巡逻、护航、轰炸等任务。值得一提的是,游戏中的地面场景乃参考GeoEye卫星空照图所构建而成,这项游戏与现实生活的科技结合,让玩家仿佛置身于战机的驾驶舱内,逼真的地表风貌一览无遗。

>>游戏类型:DirectX11 飞行模拟射击游戏
>>
>>画质设定:全部最高




《汤姆克兰西:鹰击长空2》游戏对Tessellation的性能十分依赖,同时由于N卡在Tessellation数量上的绝对优势,所以表现优于N卡,即使是此次测试中的最低端N卡也比最高端A卡表现还好。
Tessellation测试-天堂2.1
● Heaven Benchmark 2.1
《Heaven Benchmark 2.1》是由俄罗斯Unigine游戏公司开发设计的一款Benchmark程序,该程序是由Unigine公司自主研发的游戏引擎设计,其支持DirectX 9、DirectX 10、DirectX 11与OpenGL 3.2 API,通过26个场景的测试最终得出显卡的实际效能。

>>游戏类型:DirectX 9/10/11及OpenGL Benchmark
>>
>>画质设定:全部最高


《天堂2.1》Benchmark测试中,其同样对产品的Tessellation性能十分依赖,而AMD方面由于无论中高低端产品均仅为一个Tessellation单元,所以性能表现不济NVIDIA产品,其中拥有16个Tessellation单元的GeForce GTX 580表现最佳。
PhysX游戏-蝙蝠侠之阿卡姆疯人院
● Batman
《蝙蝠侠:阿卡姆疯人院》将给玩家带来一场不同寻常的,阴暗并且富有戏剧性的冒险历程,我们将抵达阿卡姆疯人院的最深处--位于哥谭市用来关押精神病犯人的精神病院.玩家将在黑暗中前行,带给敌人以恐惧,并且和小丑以及那些控制了疯人院哥谭市最臭名昭著的恶棍们一决胜负。灵活运用蝙蝠侠的各种小道具以及他的能力,玩家将化身成为不可阻挡的镇压者阻止小丑那疯狂的阴谋。

>>游戏类型:DirectX9 第三人称游戏
>>测试方式:
>>画质设定:可设置的全部最高


在PhysX游戏《蝙蝠侠:奥卡姆疯人院》测试中,由于NVIDIA产品支持PhysX-GPU技术,所以在游戏表现上N卡以绝对优势领先A卡。
应用性测试-Media Coder NT
应用性测试-Media Coder NT
MediaCoder是一个免费的通用影音转码工具,它将众多来自开源社区的优秀音频视频编解码器和工具进行整合,让用户可以自由地转换音频和视频文件,可满足各种场合下的转码需求。软件自2005年问世以来,被全球广大多媒体爱好者广泛使用,曾经入围SourceForge.net优秀软件项目,被众多网站和报刊杂志介绍和推荐,其中包括:《CNET》、《PC World》、《ZDnet》、《USA Today》、《New York Times》、印度《Techtree》、德国《Der Spiegel》、德国《Bild》、德国《La Nación》、墨西哥《El Universal》、泰国《Bangkok Post》、德国《Chip》、俄罗斯《Computerra》。

GeForce GTX 580计算能力为2.0版本

视频编码时间为16秒
MediaCoder NT这款针对CUDA编程的软件,对于所有N卡用户来说都是一个好消息。
我们使用GeForce GTX580 772MHz/1544MHz/4008MHz产品进行测试,由于该款软件对Shader频率数量极为敏感,所以1544MHz的频率作用下仅耗时16秒。
应用性测试-超频及SLI性能测试
应用性测试-超频及SLI性能测试
本环节针对GeForce GTX 580的超频能力及SLI性能做了一个测试,超频软件使用NVIDIA Inspector 1.91。测试项目选择了3Dmark Vnatage Performance模式。

● GeForce GTX 580超频测试



● GeForce GTX 580 SLI测试



我们知道Fermi架构产品中GF104和GF106的超频能力非常出色,而GF100的超频能力很多用户都是望而却步,毕竟默认频率下的功耗及发热量已经让很多消费者……
但是GF110核心的超频能力着实让笔者为之惊叹,使用NVIDIA Inspector软件经过简单的调校,产品频率轻松超至900MHz/1800MHz/4400MHz,此时性能得到大幅提升。
在3Dmark Vantage Performance测试中,超频后GeForce GTX 580轻松破3万分,而SLI模式默认频率更是突破4万分。
应用性测试-反锯齿性能衰减
应用性测试-反锯齿性能衰减
Fermi架构第一款产品GF100到来之时,NVIDIA宣称其支持目前单芯产品最高的32倍反锯齿,同时还表示Fermi架构在反锯齿性能损失上很小。那么在GF110这款新旗舰产品上,又会有何表现,我们将通过3Dmark 06和Battlefield:Bad Company 2两个项目进行对比测试。

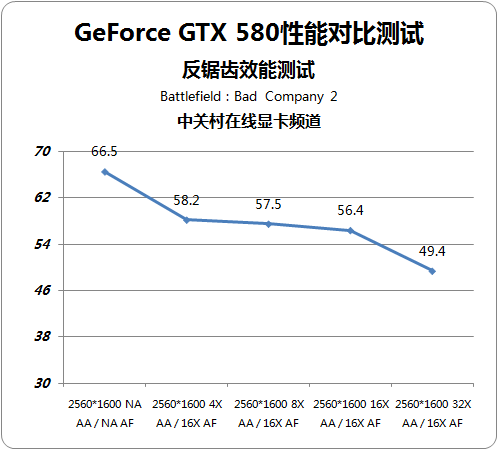
通过实际性能测试我们能够看出,32倍反锯齿确实能够为游戏带来最佳的画质,同时GeForce GTX 580即使在32倍反锯齿下依然能够保证游戏流畅运行。
同时值得一提的是,GF110核心在4倍、8倍及16倍反锯齿模式下,性能损失很小。确实如同GF100核心一样,用极小的性能损失换来更高的游戏画质。
应用性测试-Tessellation性能衰减
应用性测试-Tessellation性能衰减
Tessellation的性能直接决定了DirectX 11产品的性能表现,而根据微软的SDK Sub11 DEMO我们了解到Tessellation被化为31个等级,而在实际游戏游戏设计公司认为Tessellation等级为6时已经能够满足目前游戏需求,这也许就是AMD现阶段仅设计1个Tessellation的原因,也是A卡在DirectX 11测试中表现平平,但在实际游戏中并不落后的原因。
不过NVIDIA的设计比较前卫,虽然现阶段Tessellation的性能无需过多Tessellator,但是NVIDIA考虑到用户未来的使用,所以直接将Tessellation设计到位,尽量做到用户未来一段时间内无需升级,产品生命期更长。
下面我们就使用微软SDK Sub11针对目前NVIDIA和AMD千元以上所有产品进行一个Tessellation性能衰减测试。

(可点击放大)

(可点击放大)
通过实际测试我们可以看到,参测的NVIDIA和AMD所有产品在Tessellation等级小于5时,A卡的性能表现尚可,但是到达6级以后性能急剧下降,无论是高端还是中低端产品都无济于事。
反观NVIDIA产品,在Tessellation等级位于11级之前,性能衰减非常缓慢,虽然在12级以后性能也有明显衰减,但是衰减幅度远低于AMD产品,同时高端NVIDIA产品在Tessellation等级为31级时仍能确保测试的流畅性,NVIDIA的DirectX 11真实实力得以发挥。
应用性测试-产品实际功耗考验
应用性测试-产品实际功耗考验
除了3D性能外,用户现在也非常关心显卡的功耗问题,本环节将针对这点进行有针对性的测试。
测试方法上,待机环境下的功耗,均为开机后不做任何操作,10分钟后,功耗值平稳后记录。而温度和功耗的峰值,则是运行Furmark v1.82软件,在运行15分钟后,待温度、噪音和功耗值平稳后记录。




GeForce GTX 580 SLI模式功耗情况


GeForce GTX 580单卡功耗情况
在功耗测试中,GeForce GTX 580的单卡整机待机和满载功耗分别是140瓦和359瓦,相比原GF100核心产品及Radeon HD 5870而言,这个功耗表现非常出色,从原来GF100的功耗大户变成了现在的节电先锋。
GeForce GTX 580的Power Limiter功能对显卡长期满载时进行频率调整,以便将整卡控制在一个较为合理的功耗范围内,而Furmark不幸“中招”,所以GeForce GTX 580功耗测试,笔者挑选了一个相对功耗负载较大的游戏进行测试。
应用性测试-产品温度/噪音考验
应用性测试-产品温度/噪音考验
在温度测试中,首先笔者会在系统运行Fumark + GPU-Z程序烤机模式,连续运行20分钟以上待峰值温度恒定后,通过温度监控软件记录恒定后温度,同理在待机状态下记录待机平均温度。
温度测试平台未采用整机密闭环境测试,由于测试环境无法保证恒定温度,室温在25°C-27°C之间。由于上述不定因素的存在,所以本环节温度测试仅供参考。
在温度测试中,首先笔者会在系统运行Fumark + GPU-Z程序烤机模式,连续运行20分钟以上待峰值温度恒定后,通过噪音仪记录噪音值,同理在待机状态下记录噪音值。
● GeForce GTX 580温度测试

待机核心温度

满载核心温度


待机显卡外围温度


满载显卡外围温度
● GeForce GTX 580噪音测试


温度测试:GeForce GTX 580的待机平均温度为46°C、满载峰值温度为90°C,这样的表现相比GeForce GTX 480产品来说有了很大的降低。值得一提的是,即使GeForce GTX 580满载较长一段时间后,徒手摸显卡并不会有烫手无法坚持的感觉,GeForce GTX480的高温时代已过。
噪音测试:也许用户会想,获得前面介绍的温度成绩是否会以牺牲噪音,用高转离心式风扇增加风量从而降低温度。其实不然,在实际测试中GeForce GTX 580的待机平均噪音仅为51.1分贝,这个数值与公版GeForce GTX 460产品成绩相当,也就是说用户在GPU低负载运算时根本不会听到风扇噪音。在显卡满载一段时间后,随着温度的上升风扇转速提升,与此同时风扇噪音为77.2分贝。虽然此时噪音明显,但是相比GeForce GTX 480而言还是有了长足进步。
百花齐放 GTX580发布厂商集体跟进
百花齐放 GTX580发布厂商集体跟进
NVIDIA拥有雄厚的群众基础,同时也有数量众多合作密切的品牌商,每当NVIDIA一有新品发布,所有核心合作伙伴都会第一时间跟进。下面是本次收到送测产品,同时还有未送测但与本站确定市售相关产品的品牌。
★ 送测相关产品一览
● 映众GeForce GTX 580

映众GeForce GTX 580
● 影驰GeForce GTX 580

影驰GeForce GTX 580
● 七彩虹GeForce GTX 580

七彩虹GeForce GTX 580
★ 未送测但确定市售相关产品
● 翔升GeForce GTX 580

翔升GeForce GTX 580
● 太阳花GeForce GTX 580

太阳花GeForce GTX 580
● 旌宇GeForce GTX 580

旌宇GeForce GTX 580
旗舰也有性价比产品 GTX580可以买
旗舰也有性价比产品 GTX580可以买
当AMD发布第一款DirectX 11产品,当AMD领先NVIDIA布线完成第一代DirectX 11产品,当NVIDIA发布第一款GeForce GTX 480备受争议,当GeForce GTX 460发布力挽狂澜,当AMD再次率先发布第二代DirectX 11产品,当……
当这一切发生后NVIDIA并没有乱了阵脚,反而是有条不紊的在Radeon HD 6800发布20天后也推出了第二代产品——GeForce GTX 580。这款产品并没有重蹈GeForce GTX 480的高温、高功耗覆辙,同时延续了GF104和GF106的低功耗、低温和超频能力强的优良传统。同时GeForce GTX 580定价仅为3999元,相比GeForce GTX 480的3888元来说,性价比十分突出。
● 高端市场波澜再起 HD6900欲战GTX580
GeForce GTX 580今日发布后不久,AMD将会推出DirectX 11第二代顶级单芯产品——Radeon HD 6970,根据目前已有的网络信息汇总,其改变现有已经使用了3年5代的4D+1D流处理器设计,改为全新的4D设计,这样设计的好处是降低仲裁器和驱动仲裁机制的设计瓶颈,提高流处理器利用率,这也就意味着性能的提升。
同时根据目前已有消息来看,Radeon HD 6970并没有增加Tessellation数量,也就是说Tessellation性能不会有质的变化。但3D性能的提升也许会对GeForce GTX 480和GeForce GTX 580产生挑战。而且最重要的是,在DirectX 11产品中NVIDIA官方并没有推出一款双芯单卡产品,而AMD已经有一款Radeon HD 5970,同时Radeon HD 6990也发布在即,最强的DirectX 11单卡花落谁家仍是悬念。
虽然GeForce GTX 580从本次的测试中表现非常出色,但是是否能抵御得住Radeon HD 6900系列的强烈攻势,本月将会揭晓。不过这一切都是NVIDIA和AMD在高端产品中的竞争,对于主流用户和主流产品而言影响不大。

GF100-375-A1核心
● GF104全规格产品蓄势待发 等待HD6000
NVIDIA和AMD均发布了第二代DirectX 11产品,这也拉开了两家新一轮新品发布狂潮。而我们知道NVIDA在GeForce 400系列产品中,绝大多数产品都使用了非满规格的核心。也许这些产品的满规格产品将直接作为GeForce 500系列的原型等待Radeon HD 6000的挑战。
就像GF100向GF110转变一样,并非一成不变的换汤不换药,经过精心改良产品得到的不仅仅是性能提升,功耗、发热量也得到了很好的改善。而例如GF104、GF106等核心,是否也会像这样改变,虽然笔者不敢肯定,但这也是NVIDIA快速对应Radeon HD 6000的最佳方案。同时,GeForce GTX 468或者GeForce GTX 560这样的型号也许会在不久将来,被用户所知,同时抵抗Radeon HD 6800系列。
谁是当今真DX11显卡?!
笔者所指的真DX11显卡,并非是说真假DirectX 11显卡,因为NVIDIA和AMD的产品都是真的DirectX 11显卡。笔者所问的真DX11显卡,是指产品在DirectX 11应用中的表现,同时给用户带来的投入产出比是否更高。
我们知道,现阶段的DirectX 11应用只要集中在DirectX 11游戏中,而DirectX 11游戏的Tessellation还处于低等级应用,所以AMD当前的1个Tessellation架构设计在目前应用中还能达到及格线,不过在未来当Tessellation应用复杂度提高,现有的AMD核心架构必然捉襟见肘。当然,笔者不否定AMD未来会在适当的阶段完善GPU的架构,例如在Radeon HD 6900中也许就会适时的改变Shader架构,与时俱进是一个视觉技术公司必有得条件。
但,就目前来说NVIDIA的Fermi架构无意是最佳的DirectX 11应用搭档,无论是在DirectX 11并行计算应用、还是DirectX 11游戏中,Fermi架构均表现突出,尤其是在GeForce GTX 580、GeForce GTX 460等低温、低功耗、高性能产品出现后。同时Fermi架构的原生多Tessellation设计,还会让用户现在购买的NVIDIA DirectX 11显卡在未来一样能够流畅应对新游戏,无需更换,这样的投入产出比无疑大大提升了NVIDIA产品的性价比。
你认为当今谁是真DX11显卡?!
