全新架构登场
Radeon RX VEGA 64采用14nm FinFET “VEGA 10”核心,集成了125亿个晶体管,核心面积为486平方毫米。相比28nm工艺的上代大核心Fiji,VEGA 10的核心晶体管规模多了整整40%,面积却缩小了18%。
基于全新VEGA架构的VEGA 10 XTX芯片共有4096个流处理器,运算单元数量为64个,TMUs总数量为256个,ROPs数量为64个,两个带宽为1024-bit的双通道显存控制器组成了总量为2048-bit的显存控制单元,大小为8GB。

Vega 10核心
Radeon RX VEGA 56同样采用14nm FinFET “VEGA 10”核心,基于全新VEGA架构的Vega 10 XT芯片共有3584个流处理器,运算单元数量为56个,TMUs总数量为144个,ROPs数量为32个,两个带宽为1024-bit的双通道显存控制器组成了总量为2048-bit的显存控制单元,大小为8GB。
| 显 卡 规 格 比 较 表 | ||||
| 显卡型号 | RX Vega 64 | RX Vega 56 | GTX 1080 | GTX 1070 |
| 首发限价 | ¥4899 | ¥4199 | ¥5399 | ¥3499 |
| GPU代号 | Vega 10 XTX | Vega 10 XT | GP104-400 | GP104-300 |
| GPU工艺 | 14nm | 14nm | 16nm | 16nm |
| GPU晶体管 | 12.5B | 12.5B | 7.2B | 7.2B |
| 着色器数量 | 4096 | 3584 | 2560 | 1920 |
| 单精度浮点 | 12.7 T | 10.5 T | 9 T | 6.5 T |
| ROPs数量 | 64 | 56 | 64 | 64 |
| 纹理单元数量 | 256 | 256 | 160 | 120 |
| 核心频率 | 1274 MHz | 1156 MHz | 1607 MHz | 1506 MHz |
| boost频率 | 1546 MHz | 1471 MHz | 1733 MHz | 1683 MHz |
| TDP | 295W | 210W | 190W | 150W |
| 显存频率 | 945 MHz | 800 MHz | 1250 MHz | 2000 MHz |
| 内存位宽 | 2048 bit | 2048 bit | 256 bit | 256 bit |
| 内存带宽 | 484 GB/s | 410 GB/s | 320 GB/s | 256 GB/s |
| 内存类型 | HBM2 | HBM2 | GDDR5X | GDDR5 |
| 内存容量 | 8 GB | 8 GB | 8 GB | 8 GB |
注:表中售价均为官方首发限价
我们可以看到,Radeon RX VEGA 64水冷版的默认核心频率达到了1406MHz,Boost频率高达1677MHz,有效频率更是可以达到1750MHz,这个频率是AMD显卡史上的最高频率。RX VEGA 64显存带宽为484 GB/s,默认Pixel Fillrate能力达到了98.9Gpiexls/S,默认Texture Fillrate能力为395.8Gtexels/S;RX Vega 56显存带宽为410 GB/s,默认Pixel Fillrate能力达到了94Gpiexls/S,默认Texture Fillrate能力为330Gtexels/S。
凭借高频和庞大的运算规模,RX VEGA 64最高拥有13.7 TFLOPS的超高单精度浮点运算能力,照比上代R9 Fury X提升了59.3%,提升幅度相当惊人,是目前单芯显卡中单精度浮点运算性能最强的。
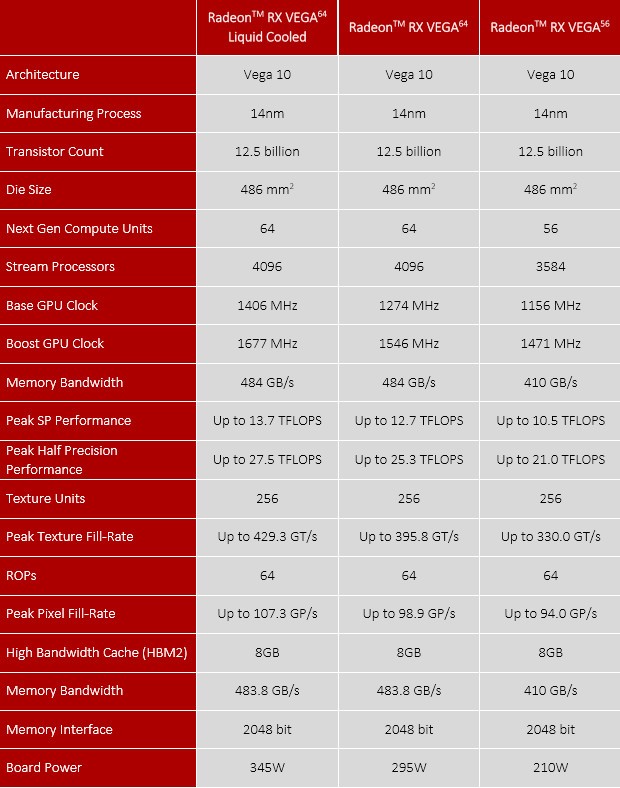
RADEON RX VEGA家族参数一览
VEGA 10芯片具备以下特点:
1、基于14nm LPP FinFET工艺。
2、64组NCU单元被分为4个Compute Engines,每个Compute Engines包含16组NCU。NCU是GCN架构引入以来最大规模的底层革新,其加入了快速堆叠运算(Rapid Packed Math/RPM),每时钟周期可以处理512个8位、256个16位或者128个32位操作,尤其是可以在单个FP32 ALU内处理一对FP16浮点操作,如果两个FP16操作彼此兼容的话,就可以打包到一起作为FP32进行处理,由此带动峰值吞吐能力的翻倍。同时,寄存器还可以把一个FP32拆分成两个FP16,进行反向操作。NCU单元针对高频率、高IPC都进行了优化,可以同时进行计算和图形处理,并且能够根据负载不同而变换SIMD单元宽度,以往需要多个计算单元才能完成的任务,现在只需一个就能搞定,不会造成GPU性能上的浪费。
3、与Compute Engines一一对应的4组Geometry Engine(几何引擎)以及4组DSBR(绘制流分档光栅器)。DSBR可以消除GPU上非必要的处理和数据传输,提升性能、降低功耗,AMD称DSBR能在游戏中获得10%的帧率提升,同时节约最多33%的显存带宽,而且不会增加功耗。
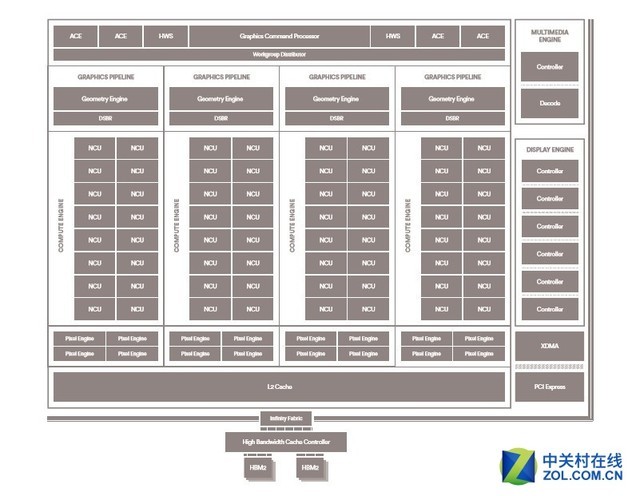
VEGA 10核心架构图
4、ACE异步计算单元的总量为4组,同时还有2组为异步运算设计的HWS加入到架构中。HWS用来更好地对硬件资源进行调度,提高异步运算效率。
5、二级缓存达到了4MB,在降低显存带宽需求的同时改善电源效率,在显存运行上更节能。
6、采用来自美光的新一代HBM2显存,单位带宽是第一代HBM的2倍,达到了2Gbps/pin,单Die容量高达一代4倍,占用面积相比GDDR5显存降低了50%。
7、为了更好地发挥HBM2显存的优势,在VEGA中,AMD加入了高带宽缓存控制器(HBCC),该控制器用来管理HBM2、系统内存、非易失性内存和网络存储。HBCC的最大虚拟寻址空间高达512TB,可以适应并管理超大数据集,并可精细调节数据的转移。HBCC被视为VEGA架构中最大的革新,简单地说可以把整个系统内存当做显存来使用,相当于一块显卡可以拥有TB级别的高速显存,换言之,它实现了某种程度上的一体化内存池,这部分AMD称之为“HBCC内存区”(HMS)。
8、VEGA 10是AMD第一款采用“Infinity Fabric”技术的GPU,该技术将GPU同内存控制器、PCI-E控制器、显示引擎和视频加速模块等主要逻辑模块连接起来。这种模块化的设计让GPU可以根据客户的不同需求进行变换,其也被应用于AMD“Zen”架构CPU上。
本文属于原创文章,如若转载,请注明来源:狙杀GTX 1080/1070 RX VEGA 64/56首测//vga.zol.com.cn/650/6506036.html















































