AMD黄金架构HD5000大战Fermi
● 从R600到RV870艰难磨砺
将R600的流处理器数目翻2.5倍,其他单元做进一步优化,AMD造就了成功的RV770,那RV770的规模还能否继续放大?放大后发热和功耗是否能够控制?是冒险尝试新工艺还是使用稳定的55nm工艺制造……
回忆2007年秋季,RV770诞生之后,图形业界对于AMD的下一款产品充满了期待。NVIDIA也计划在G92的基础上再度推出GT2X0等中低端芯片规格以抢占市场,当然AMD没有忘记,当时的单卡单芯性能最强的仍然是GTX285,而并非自己的产品。

在这种紧要关头,AMD下一代旗舰——RV870的规格备受瞩目,它肩上的责任也异常重大,首先AMD寄希望于这款核心能够完全扭转高端市场的战局,击败后的GTX280;同时AMD希望能够通过RV870核心衍生出纷繁复杂的产品线,这样就能进一步加大市场占有率。
当然我们所期待的RV870,并不是此时开始设计,按照GPU的设计周期和最后的资料推断,2006年AMD在内部已经开始了对RV870芯片的讨论,它起初被命名为“Evergreen”。
2009年09月23日,AMD为我们带来了基于DirectX 11的Radeon HD5870显卡。它采用第二代40nm工艺制造、搭载第四代GDDR5显存、拥有1600个流处理器、Eyeinfinty多屏显示技术、超低待机功耗等。最为关键的是Radeon HD5870满足了DirectX 11的一切设计要求,同时取得了对NVIDIA上一代顶级单卡Geforce GTX285的全面领先。无论是技术、规格还是性能,AMD用数据说话证明了自己再一次登上GPU王座。
RV870的成功在于多个方面,首先它率先支持了微软的DirectX 11硬件要求,这是NVIDIA当时的产品无法触及的。同时从性能角度讲,自从Radeon 1900XT在Geforce 8800GTX的打压下失去性能皇冠后,Radeon HD5870再次夺回了顶级显卡的王位。更重要的是,AMD在R300之后首次取得了时间、性能、规格上的三重领先。现在,AMD最大的芯片比NV最大的芯片更快。不仅如此,它还比NV最大的芯片要小,而且更便宜。

HD5800系列显卡呼之欲出
在2009年12月下旬,台积电宣布TSMC 40nm工艺良率已达到稳定,这更给AMD的Radeon HD5000系列产品打了一针强心剂,HD5000系列产品的供应量随之得到增长。
下面就让我们来预览一些AMD的Radeon HD5870产品的重要特性:
·第一款支持DX11的GPU,微软的所有要求AMD都非常精准地完成;
·第一款制程进入40nm线宽的GPU,晶体管数目突破21亿;
·第一款浮点运算能力超过2TeraFlops的GPU,RV770是当时业界第一款超越1TFLOPS大关的GPU;
·第一款具备民用级别多屏幕显示能力的GPU,实现3屏甚至6屏显示不再需要代价高昂的专业设备。
回顾Radeon HD 2000到HD5000系列产品的发展历程,我们首先把架构扩张的头等功记在SIMD结构的流处理器身上。使用了VLIW技术的SIMD结构流处理器以较小的晶体管消耗获得了强大的规模效应。同时虽然这种结构在效率上明显输给MIMD结构,但是它在遇到全4D指令或者大量的4D指令时,可以爆发出澎湃的指令吞吐量,而目前的很多游戏中还是大量掺杂着4D指令,这为SIMD结构的流处理器性能发挥奠定了基础。

Radeon HD5000系列产品带来了性能的大幅度增长
所以当我们回顾GPU在同一渲染时代的发展历程时,我们不得不把这种较为传统的SIMD结构流处理器放在比较重要的位置来思考。NVIDIA一次次改进架构却难以换来大幅度的性能提升,AMD不断堆砌流处理器数量,甚至减少了每个流处理器周边资源的配置,还是保证了GPU的快速向前;不但如此还有功耗问题,GT200架构开始,NVIDIA已经不得不把功耗作为一个很重要的参考因素来设计GPU,而AMD则表现地轻松很多,典型例子就是两款性能不相上下的产品——GTX260+和HD5770,基于RV840的HD5770在提供了比肩GTX260+的性能前提下,消耗的电力约为对手的1/2,这就是技术进步的重要体现。
除了规模上的扩张,RV870还竭力弥补了R600架构之前遗憾。过去,由于过分注重成本,从R600开始AMD家族的通用运算能力就落后对手不少。AMD在RV870上着重改进了这一点,新加入的LDS(Local Data Share)有效提升了存储性能,改善了流处理器的执行效率。RV870不但支持微软DirectCompute和苹果OpenCL通用计算平台,还重新优化了数据共享结构,提供了完整的多级缓存供流计算使用,并且优化了访存能力。抢占式多线程虽然在技术层面略逊于Fermi的多级多分配并行多线程设计,但是就技术的标准来讲,RV870与对手站到了同一起跑线上。
ATI架构优势与特性明显
● ATI黄金架构优势与特性
AMD从R600核心开始,一直延续着上述理念设计GPU产品,R600身上有很多传统GPU的影子,其Stream Processing Units很像上代的Shader Units,它依然是传统的SIMD架构。这些SIMD架构的5D ALU使用VLIW技术,可以用一条指令完成多个对数值的计算。
由于内部的5个1D ALU共享同一个指令发射端口,因此宏观上R600应该算是SIMD(单指令多数据流)的5D矢量架构。但是R600内部的这5个ALU与传统GPU的ALU有所不同,它们是各自独立能够处理任意组合的1D/2D/3D/4D/5D指令,完美支持Co-issue(矢量指令和标量指令并行执行),因此微观上可以将其称为5D Superscalar超标量架构。

AMD的流处理器结构变化
SIMD虽然很大程度上缓解了标量指令执行效率低下的问题,但依然无法最大限度的发挥ALU运算能力,尤其是一旦遇上循环嵌套分支等情况,SIMD在矢量处理方面高效能的优势将会被损失殆尽。同时VLIW的效率依赖于指令系统和编译器的效率。SIMD加VLIW在通用计算上弱势的原因就在于打包发送和拆包过程。
NVIDIA从G80开始架构作了变化,把原来的4D着色单元彻底打散,流处理器不再针对矢量设计,而是统统改成了标量运算单元。每一个ALU都有自己的专属指令发射器,初代产品拥有128个这样的1D运算器,称之为流处理器。这些流处理器可以按照动态流控制智能的执行各种4D/3D/2D/1D指令,无论什么类型的指令执行效率都能接近于100%。

AMD的流处理器结构精简节约
AMD所使用的SIMD结构流处理器,具有非常明显的优势就是执行全4D指令时简洁高效,对晶体管的需求量更小。而NVIDIA为了达到MIMD流处理器设计,消耗了太多晶体管资源,同时促使NVIDIA大量花费晶体管的还有庞大的线程仲裁机制、端口、缓存和寄存器等等周边资源。NVIDIA为了TLP(线程并行度)付出了太多的代价,而这一切代价,都是为了GPU能更好地运行在各种复杂环境下。
但是业界普通的共识是SIMD结构的流处理器设计能够有效降低晶体管使用量,特别是在已经设计好的架构中扩展流处理器数量的难度,比起MIMD结构要容易很多。对比R600和G80架构可知,4个1D标量ALU和1个4D矢量ALU 的理论运算能力是相当的,但是前者需要4个指令发射端和4个控制单元,而后者只需要1个,如此一来MIMD架构所占用的晶体管数将远大于SIMD架构。
HD5870核心亮相 设计精简实用
● HD5870核心亮相 设计精简实用
AMD的RV870流处理器数量可谓大幅激增,相对上一代RV770/RV790的800SPs有了翻倍设计,同时21.5亿的晶体管数量也相对有了2.2倍以上的增加,我们知道基于55nm工艺的RV770核心面积为260mm2,如果想使用55nm工艺制造RV870核心,这几乎是一项可以实现但不切实际的做法,接近600mm2的核心面积成本不菲。Radeon HD 4770的40nm核心——RV740为RV870奠定了量产基础,从而解决了RV870在工艺及成本上的问题。

40nm工艺RV870核心
Radeon HD 5870搭载的RV870核心由台积电(TSMC)采用40nm工艺生产,其拥有1600个流处理器、32个光栅处理器和80个纹理单元。此次AMD的产品线升级,最重要的就是完美支持DirectX 11 API和Shader Model 5.0,而且值得一提的是DirectX 11 API中新加入了Direct Compute Shader,这也是微软在GPU通用计算上的一次大踏步跃进,而且这也证明GPU未来在通用计算领域的重要性。

21.5亿晶体管 核心面积仅为330mm2
前文我们说过RV870如果不采用全新的40nm工艺制造,将会带来高成本、高功耗、高发热量的诸多弊端,而采用40nm工艺后可以说药到病除,问题迎刃而解。
RV870相对RV770在增加了2.2倍以上晶体管数量的前提下,核心面积仅增加了不到27%,即从RV770的260mm2仅增加到330mm2。RV870核心为正方形设计,我们使用电子游标卡尺实际测量边长约为18.92mm,与实际的18.17mm有测量误差。

RV870核心架构

RV770核心架构
对比RV870和RV770核心架构我们发现,RV870并非RV770一样将1600个流处理器设计在同一区域,而是将1600个流处理器分为2组各800。
我们知道统一架构能够更加合理的利用每一个流处理器(Stream Processor),而且每个流处理器均能服务于顶点、像素、几何乃至DirectX 11引入的Direct Compute Shader,这种通用性可以充分利用GPU的并行架构。
在从AMD第一代统一架构图形芯片出世以来,均是采用SIMD设计,与以往不同的是RV870的SMID Cores被分为两部分。这样的设计更有理由图形核心的设计以及产品良率的提高,但这样的弊端就是需要对核心内部的线程控制器及驱动仲裁机制提出了严峻挑战。
首先核心需要一个叫做“Ultra-Threaded Dispatch Processor”(超级线程控制器)来整体分配流处理器处理,然后交由两组的流处理器进行计算,最后交由ROP(光栅处理器)最后进行AA(反锯齿)处理,同时在“Global Data Share”中的纹理贴图直接进入L2 Cache。最终在每组内存控制器的作用下,将ROP和L2 Cache的数据汇总输出。
Fermi架构过于臃肿庞大
● Fermi架构过于臃肿庞大
我们知道全规格Fermi架构产品拥有512 CUDA Cores,而作为顶级的单芯产品GeForce GTX 480并没有标配全规格图形处理核心,而是缩减了1组SM后得到核心,这是让笔者和众多消费者没有想到的。不过笔者分析,GeForce GTX 480标配非全规格图形核心的原因主要有三:其一、该核心足以满足用户需求,同时能够镇压竞争对手顶级产品;其二、处于功耗以及成本方面的综合考虑;其三、提高GF100图形核心良率。当然这些仅是笔者个人猜测,不代表本站和NVIDIA官方意见,但无论怎样GeForce GTX 480的发布确实对图形核心发展有着重要的意义。

基于40nm工艺的GF100-375-A3核心
GeForce GTX 480标配的GF100-375-A3核心是由台积电(TSMC)采用40nm工艺制造,其共有32亿晶体管,是目前最庞大的图形处理核心。用于GeForce GTX 480的GF100核心拥有480个流处理器、60个纹理单元、48个光栅处理器,同时标配384bit显存控制器。
Fermi架构的GF100芯片相对于早期G80架构(G80架构影响了G8X、G9X和G200架构设计),除了常规的流处理器数量等参数升级外,Fermi架构相对G80架构做了重大调整,例如在Cache、SM架构等等方面做了改革,目的是让GF100核心适应现在甚至未来的用户应用需求。例如,Fermi架构图形核心引入了真正可读写L1/L2缓存,新增了Polymorph Engines和Raster Engines引擎等。
Fermi架构GF100核心 新增强劲神器引擎
当然仅是在数量优化上做改变还不能称为第二代CUDA架构,我们在GF100核心架构图和SM架构图上可以看到,相比G80/92和GT200核心架构多了Polymorph Engines和Raster Engines功能模块组。那么它们又是做什么的呢?

全新的Polymorph Engines和Raster Engines
我们可以这样简单的理解,在数据处理流程中的一些功能模块现组成了现在的Polymorph Engines和Raster Engines。其中Polymorph Engines包括Vertex Fetch、Tessllator、Viewport Transform、Attribute Setup和Stream Output,Raster Engines包括Edge Setup、Raterize和Z-Cull。

GF100对比RV870 Tessellation性能
值得一提的是DirectX 11中Tessellation功能是必不可缺的,而Tessellator并不是使用SP来完成,而是采用独立功能模块完成,在这一点上与AMD的做法一致。但不同的是,AMD的Tessellator采用串行计算模式,也就是说核心中只有一个Tessellator功能模块,数据计算从分配到接收Tessellator会成为瓶颈。反观NVIDIA的GF100核心,每组SM拥有一个Polymorph Engines,这也就意味着一个GF100核心拥有16个Tessellator功能模块,在Tessellation多数据并行计算方面GF100遥遥领先RV870。

Polymorph Engines和Raster Engines在GF100中的设计
前文提过每组SM都会标配一个Polymorph Engines,同时每组GPC将独立拥有一个Raster Engines,这样的设计都是增加各种数据计算的并行效果,相比RV870的非Shader计算串行设计要优越很多。
Fermi具备的光栅并行化是一个重要创新。NVIDIA称Fermi GF100是一个全新架构,不但是通用计算方面,游戏方面它也发生了翻天覆地的变化,几乎每一个原有模块都进行了重组:有的砍掉了,有的转移了,有的增强了,还有新增的光栅引擎(Raster Engine)和多形体引擎(PolyMorph Engine)。

光栅引擎(Raster Engine)
光栅引擎严格来说光栅引擎并非全新硬件,只是此前所有光栅化处理硬件单元的组合,以流水线的方式执行边缘/三角形设定(Edge/Triangle Setup)、光栅化(Rasterization)、Z轴压缩(Z-Culling)等操作,每个时钟循环周期处理8个像素。GF100有四个光栅引擎,每组GPC分配一个,整个核心每周期可处理32个像素。

多形体引擎(PolyMorph Engine)
多形体引擎则要负责顶点拾取(Vertex Fetch)、细分曲面(Tessellation)、视口转换(Viewport Transform)、属性设定(Attribute Setup)、流输出(Stream Output)等五个方面的处理工作,DX11中最大的变化之一细分曲面单元(Tessellator)就在这里。Fermi GF100产品中有16个多形体引擎,每个SM一个,或者说每个GPC拥有四个。
凭借多形体PolyMorph引擎,Fermi实现了全球首款可扩展几何学流水线,该流水线在单颗GPU中包含了最多16个Tessellation引擎。这些引擎在DirectX 11最重要的全新图形特性GPU加速Tessellation中能够发挥出革命性的性能。通过将更加细腻的几何图形融入到场景当中,Tessellation让开发人员能够打造出视觉清晰度极高、更加复杂的环境。锯齿边缘平滑了,从而使游戏中所渲染出来的人物能够拥有影院般细腻的画质。
在以前的架构中,固定功能单元只是单一的一条流水线。而在GF100,无论是固定功能单元和可编程操作单元都并行设计,这大大提高图形性能,也解决了GPU长期以来未有重大突破的性能短板。
多形体PolyMorph引擎的出现,是几何流水线近几年间不断演化的重大突破。特别是细分曲面操作,需要的三角形和光栅能力都异常可怕,传统GPU无法应对。多边形引擎的出现大幅度提高了三角形、细分曲面和流输出能力。通过给每个SM搭载属于自己的细分曲面Tessellation硬件单元,并为每个GPC搭载属于自己的光栅化引擎,GF100最终为我们提供了高达8倍于GT200几何性能。
曲面细分不需要被夸大
● 曲面细分不需要被夸大
Tessellation又可译作拆嵌式细分曲面技术。其实这是ATI早在其第一代DirectX 10图形核心R600,即HD2900XT上就引入的一个特殊的计算模块。从HD2000系列开始,直到最新的HD5000系列,整整4代显卡全部支持这一技术。即使目前也仍然没有游戏能够支持这一技术,ATI也依然没有放弃在这项技术上的努力——从名字上也可以看出ATI在这项技术上的心血:Tessell-ATI-on。
Tessellation主要是靠GPU内部的一个模块Programmable Tessellator(可编程拆嵌器)来实现的。能够根据3D模型中已经有的顶点,根据不同的需求,按照不同的规则,进行插值,将一个多边形拆分成为多个多边形。而这个过程都是可以由编程来控制的,这样就很好的解决了效率和效果的矛盾。TessellATIon能自动创造出数百倍与原始模型的顶点,这些不是虚拟的顶点,而是实实在在的顶点,效果是等同于建模的时候直接设计出来的。

Tessellation工作流程三部曲
很明显,DirectX 11中的Tessellation让雪山的凹凸感更为明显,远胜于DirectX 10里所采用的视差映射贴图技术。虽然后者在较远距离观看的时候也能提供一定的视觉欺骗性,但和 Tessellation技术塑造出来的真实感觉还相差太远。我们使用的分析图来自AMD在R600发布时放出的一段Demo,这段Demo区别于以往的设计方式,它没有突出主角而淡化背景,因为在没有Tessellation技术之前,大量顶点的生成和随之而来的计算将给GPU的几何处理部分带来巨大压力,无法流畅运行,而Tessellation技术改变了这一模式。
除了大幅提升模型细节和画质外,Tessellation最吸引程序员的地方就是:他们无需手动设计上百万个三角形的复杂模型,只需简单勾绘一个轮廓,剩下的就可以交给Tessellation技术自动拆嵌,大大提高了开发效率;而且简单的模型在GPU处理时也能大幅节约显存开销,令渲染速度大幅提升。

《Heaven Benchimark 2.0》关闭Tessellation

《Heaven Benchimark 2.0》开启Tessellation Normal
《Heaven Benchimark 2.0》开启Tessellation Extreme
综上所述,通过两款曲面细分的代表Demo截图我们就会发现,当今的游戏其实并不需要把曲面分得太细,只要将插值顶点的数目控制在一定的范围之内,画面就非常精细了,盲目提高插值级别的做法没有太大意义,可谓是得不偿失。
事实上,当今所有的DX11都是这么做的,虽然使用了Tessellation技术,但都只是蜻蜓点水、适可而止,即便如此已经可以让游戏画面得到很大的改善。游戏不同于技术演示Demo或者SDK,而是本着实用化的原则,追求高效率运行,而不是专用用来刁难显卡的。
也就是说,以现有HD5000的Tessellation运算能力,是完全足以胜任今后较长一段时间内DX11游戏的需要。GTX480/470虽然拥有N倍于HD5000的Tessellation运算能力,但除了能够在为数不多的几款Demo当中蹂躏A卡外,似乎并没有其它用途。等到未来游戏真正需要更强的曲面细分性能时,当今的顶级显卡可能几百块钱处理都处理不掉了,未来的游戏同样需要更强的浮点运算能力,而不是片面注重某一特定技术的性能。
ATI Catalyst AI带来性能提升
● ATI Catalyst AI带来性能提升
在2004年,伴随着X700系列显卡的发布,ATI公司在它的驱动上新增加了一些其他的额外功能。目前我们到手的Catalyst最新版本拥有一项叫做Catalyst AI.的新技术。事实上,ATI拥有Catalyst最新版本的所有优化功能,并增加了一些其它的新特性。同时把这些优化功能和新特性归类为一个包。
Catalyst AI 技术的无论是高低设置都可以通过调整纹理滤波功能来提高性能。它们为了提高图像质量也做了相应的调整。无论在任何一个纹理时期,ATI不再会使各向异性滤波里下降为双线性滤波。(以前,如果对象最初的纹理不是最高的解决方案,一般会使用双线性滤波),如果Catalyst AI 技术被关闭掉,并且要求使用三线性滤波。那么这种方式现在可以完成任何事情。

ATI的Catalyst驱动
在测试了ATI现已公布的Catalyst支持的很多游戏之后,我们现在能够来评估一下他们的功能。他们表示过努力做到几乎没有画质上的区别,在观看游戏的时候,我们发现确实是这样。当然,我们最好在3D和UT2K4(仅仅当AA/AF激活)游戏中去观察所有的真正的改进。或许现在已经有针对“Catalyst AI”(bete驱动)特性的文章译本,或者或许对于我们测试的游戏实际上并没有性能的差别。通常我们使用更高性能的硬件突出表现在小的优化和性能的增强,并且这些游戏不应该被系统的其它方面限制。而我们对ATI明显的满意是它避免了降低到双线性过滤。
就性能来说,最新的Catalyst 10.3系列驱动在《Dirt 2》、《Tom Clancy's H.A.W.X》等官方列表提及的游戏中,确实存在较大的性能提升,不过我们对比了开启和关闭Catalyst A.I后的画质,在细节方面的变化则是难以察觉的,相信玩家在激烈的游戏当中亦不能分辨在画质上区别。

打开CATALYST A.I之后性能可以获得进一步提升
通过CATALYST A.I,用户可以在当今顶级主流游戏中得到性能提升以及全方位的游戏新体验。要说明的是,取得这样的性能提升并不是建立在牺牲画质的基础上的。由于当前开发人员在制作游戏时会使用很多不同的方法,所以已往很难去针对每一个游戏进行优化。而借助CATALYST A.I.工具,我们可以更高的解决这种不一致的情况,同时为用户带来更好的游戏体验。此外,如果没有多余的优化应用,那么游戏将按照开发者的原意进行。当程序需要时,优化措施将开始进行。

环境光遮蔽选项在NVIDIA的控制面板中默认关闭
“环境光遮蔽”(Ambient Occlusion,AO)是一种非常复杂的光照技术,通过计算光线在物体上的折射和吸收在受影响位置上渲染出适当的阴影,进一步丰富标准光照渲染器的效果。“屏幕空间环境光遮蔽”(SSAO)就是该技术的一个变种,现已用于《Crysis》、《S.T.A.L.K.E.R.:晴空》、《火爆狂飙》、《鹰击长空》、《帝国:全面战争》等游戏。
NVIDIA从GeForce 185.20 Beta驱动开始就引入了环境光遮蔽特效,最新泄露的185.65 Beta版同样支持该技术,不过仅限Windows Vista/7操作系统下。AO和SSAO非常消耗资源,开启后会造成游戏帧率大幅降低,所以只推荐高端显卡用户使用,NVIDIA驱动中的AO选项也是默认关闭的。
ATI CATALYST A.I.功能通过对纹理滤波的控制,在特定的情况下,尤其是高分辨率或高画质特效下,有效的提升了系统的实际3D效能。但在部分的OpenGL游戏中,CATALYST A.I.的开启对3D效能提升并非十分明显,相信随着ATi的不断努力,CATALYST A.I.的潜力将会得到更好的发挥。
物理加速并非PhysX专属
● 物理加速并非PhysX专属
物理引擎通过为刚性物体赋予真实的物理属性的方式来计算它们的运动、旋转和碰撞反映。为每个游戏使用物理引擎并不是完全必要的——简单的“牛顿”物理(比如加速和减速)也可以在一定程度上通过编程或编写脚本来实现。
然而当游戏需要比较复杂的物体碰撞、滚动、滑动或者弹跳的时候(比如赛车类游戏或者保龄球游戏),通过编程的方法就比较困难了。物理引擎使用对象属性(动量、扭矩或者弹性)来模拟刚体行为,这不仅可以得到更加真实的结果,对于开发人员来说也比编写行为脚本要更加容易掌握。

目前活跃的几大物理引擎及其后方厂商
Havok引擎,全称为Havok游戏动力开发工具包(Havok Game Dynamics SDK),一般称为Havok,是一个用于物理系统方面的游戏引擎,为电子游戏所设计,注重在游戏中对于真实世界的模拟。使用撞击监测功能的Havok引擎可以让更多真实世界的情况以最大的拟真度反映在游戏中。
Havok的1.0版本是在2000年的游戏开发者大会(GDC)上面发布的;2.0版本在2003年的GDC大会上发布;4.5版本在2007年3月释出。原始码在取得引擎用户许可证之后便会收到。目前,Havok可以在微软的窗口操作系统、Xbox与Xbox360,任天堂的GameCube与Wii、新力的PS2、PS3与PSP、苹果计算机的Mac OS X、Linux等操作系统或游戏主机上使用。此游戏引擎是用C语言/C++语言所撰写而成。

基于Havok物理引擎加速的游戏
最新的5.5版本在2008年2月释出。新版本的SDK更完善,更人性化。亦加入了新的物理效果,例如布料的摆动效果。在示范中,Havok利用了斗篷来表现这个效果。当人物走动的时候,其背后的斗篷会随着人的移动来摆动。破坏效果方面,新增了物体的破碎和变形。非商业应用的物理引擎是免费提供的,目的是加大普及率。随后,商业的游戏应用亦变成免费。不过商业应用但非游戏,和引擎的全部源代码,就需要付款。
自从Havok引擎发布以来,它已经被应用到超过150个游戏之中。最早,使用Havok引擎的游戏大多数都是第一人称射击类别,但随着游戏开发的复杂度与规模越来越大,其他类型的游戏也想要有更加真实的物理表现,有越来越多的其他类型的游戏采用Havok引擎,例如为实时战略游戏类型,Ensemble Studios的世纪帝国Ⅲ与暴雪娱乐的星际争霸II;竞速类型,世嘉公司的音速小子与新力发行的摩托风暴。在软件3D Studio Max和Maya 3D中也能看到已经打包为插件的Havok引擎。

由AMD主导的Havok物理引擎
但面对越来越多的3D模型和越来越多的实际特效没有物理加速是不可能的。NVIDIA收购了Ageia自然有PhysX物理加速,那AMD呢?那自然是选择应用率更高的Havok推出的Havok物理加速引擎。AMD之所以选择Havok引擎有几个原因。
第一:目前在全球游戏领域里被广泛应用的物理引擎的只有Ageia和Havok,其中Ageia被对手NVIDIA收购自然不会去选择采用。
第二:从物理引擎的游戏实际应用数量上看,使用Havok引擎的游戏约为总数量的3/4款,而使用PhysX技术的只剩下的1/4款。自然是首选Havok物理加速引擎。
第三:PhysX主要是让GPU去运算物理效果,而Havok则是让CPU+GPU联合来运算,符合AMD的GPGPU的发展线路。
性能测试的硬件、软件平台状况
性能测试的硬件、软件平台状况
● 测试系统硬件环境
测 试 平 台 硬 件
中央处理器
Intel Core i7-975 Extreme Edition
散热器
Thermalright Ultra-120 eXtreme
内存模组
Apacer PC3-12800 猎豹套装 2GB*3
(SPD:1600 8-8-8-24-2T)
主板
ASUS P6T Deluxe
(Intel X58 + ICH10R Chipset)
显示卡
AMD 产 品
Radeon HD 5970
(RV870 / 2048MB / 核心:725MHz / Shader:725MHz / 显存:4000MHz)
Radeon HD 5870
(RV870 / 1024MB / 核心:850MHz / Shader:850MHz / 显存:4800MHz)
Radeon HD 5850
(RV870 / 1024MB / 核心:725MHz / Shader:725MHz / 显存:4000MHz)
Radeon HD 5830
(RV870 / 1024MB / 核心:800MHz / Shader:800MHz / 显存:4000MHz)
NVIDIA 产 品
GeForce GTX 480
(GF100 / 1536MB / 核心:700MHz / Shader:1401MHz / 显存:3696MHz)
GeForce GTX 470
(GF100 / 1280MB / 核心:607MHz / Shader:1215MHz / 显存:3348MHz)
硬盘
Hitachi 1T
(1TB / 7200RPM / 16M
电源供应器
AcBel R8 ATX-700CA-AB8FB
(ATX12V 2.0 / 700W)
显示器
DELL UltraSharp 3008WFP
(30英寸LCD / 2560*1600分辨率)

Apacer猎豹6GB DDR3-1600套装

AcBel R8 ATX-700CA-AB8FB

Thermalright Ultra-120 eXtreme
我们的硬件评测使用的内存模组由宇瞻(Apacer)中国区总代理佳明国际提供,电源供应器、CPU散热器由华硕(ASUS)玩家国度官方店、利民(Thermalright)的北京总代理,COOLIFE玩家国度俱乐部提供。
● 测试系统的软件环境
| 操 作 系 统 及 驱 动 | |
| 操作系统 | |
| Microsoft Windows 7 Ultimate RTM | |
| (中文版 / 版本号7600) | |
| 主板芯片组 驱动 |
Intel Chipset Device Software for Win7 |
| (WHQL / 版本号 9.1.1.1125) | |
| 显卡驱动 | |
| AMD Catalyst for Win7 | |
| (WHQL / 版本号 10.3b) | |
| NVIDIA Forceware for Win7 | |
| (WHQL / 版本号 197.41) | |
|
|
2560*1600_32bit 60Hz |
| 测 试 平 台 软 件 | ||
| 3D合成 测试软件 | ||
| 3Dmark Vantage | ||
| Futuremark / 版本号1.01 | ||
| 3D游戏 测试项目 | ||
| DirectX 11 Benchmark |
Heaven Benchmark | |
| UNIGINE / 版本号 1.0 | ||
| Heaven Benchmark | ||
| UNIGINE / 版本号 2.0 | ||
| DirectX 11游戏 | Alien vs. Predator | |
| SEGA / 版本号 1.0 | ||
| Battlefield:Bad Company 2 | ||
| EA / 版本号 1.0 | ||
| Colin McRae DiRT 2 | ||
| Codemasters / 版本号 1.01 | ||
| Motre 2033 | ||
| 4A Game / 版本号 1.0 | ||
| S.T.A.L.K.E.R.:Call of Pripyat | ||
| Koch / 版本号 1.0 | ||
| Stone Giant | ||
| BitSuid / 版本号 Beta | ||
| 微软DirectX 11 SDK—Sub 11 | ||
| 微软 / 版本号 SDK | ||
| GPU通用计算 | ComputeMark | |
| / 版本号 1.1 | ||
| DirectCompute Bencmark | ||
| Copcom / 版本号0.35 & 0.45 | ||
| 辅助测试软件 | Fraps | |
| beepa / 版本号 3.1.3 | ||
各类合成测试软件和直接测速软件都用得分来衡量性能,数值越高越好,以时间计算的几款测试软件则是用时越少越好。
DX11游戏-异形大战铁血战士
● Aliens Vs. Predator
由Rebellion开发、世嘉发行的科幻射击游戏《异形VS铁血战士》(Aliens vs. Predator)现已确定发售日期。根据世嘉的《异形VS铁血战士》官方网页的信息,本作将于2010年2月19日上市,对应PC、PS3和Xbox 360平台。这部根据电影改编的游戏也同样存在着三方势力,一方是人类海军陆战队,一方是异形,还有一方是铁血战士,游戏中玩家可以选择的是海军陆战队或者是铁血战士甚至是异形。本作提供单人模式和多人模式。

>>游戏类型:DirectX11第一人称射击类游戏
>>测试方式:沿同一固定路线跑完3次取平均值,Fraps计速
>>画质设定:全部最高


DX11游戏-叛逆连队2
● Battlefield: Bad Company 2
《战地:叛逆连队2 (Battlefield: Bad Company 2) 》是EA DICE研发的第9款“战地”系列作品。它是2008年上市的同系列的游戏战地:叛逆连队的续作。两在单人游戏剧情上亦有很多交叉点。游戏仍然沿用前作的寒霜引擎,并有所改进。除了完善了代码的优化,本作在破坏效果上也有所加强,可破坏的物件由92%上升到99%。前作里不能破坏的小物件以及建筑物框架,在本作中也可以被破坏。

>>游戏类型:DirectX11第一人称射击类游戏
>>测试方式:沿同一固定路线跑完3次取平均值,Fraps计速
>>画质设定:全部最高


DX11游戏-科林麦克雷之尘埃2
● Colin McRae DiRT2
《科林麦克雷:尘埃》本身是一款为纪念去世的英国拉力赛车手科林.麦克雷(Colin McRae)而制作的游戏,因此在游戏过程中不难见到许多麦克雷过往的身影,距前作将近二年多之久的《科林麦克雷:尘埃2》于2009月12月11日正式发售。值得一提的是,这款游戏不仅拥有很高的可玩性,同时还是率先支持DirectX 11 API的游戏,一经上市就得到广大游戏爱好者争相追捧。

>>游戏类型:DirectX 11竞速类游戏
>>测试方式:
>>画质设定:全部最高


DX11游戏-地铁2033
● Metro 2033
本作题材基于俄罗斯最畅销小说Dmitry Glukhovsky。由乌克兰4A游戏工作室开发,采用4A游戏引擎,而且PC版支持nvidia的PhysX物理特效。 2013年,世界被一次灾难性事件毁灭,几乎所有的人类都被消灭,而且地面已经被污染无法生存,极少数幸存者存活在莫斯科的深度地下避难所里,人类文明进入了新的黑暗时代。直至2033年,整整一代人出生并在地下成长,他们长期被困在“地铁站”的城市。

>>游戏类型:DirectX11 第一人称视角射击游戏
>>
>>画质设定:全部最高


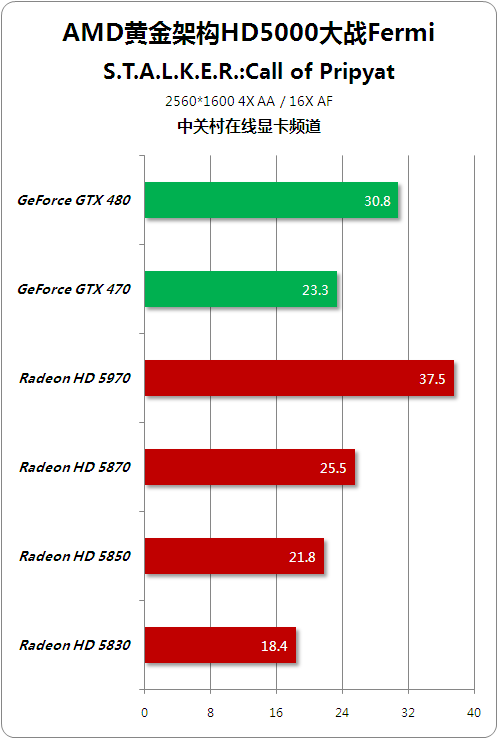
DX11游戏-潜行者之普里皮亚召唤
● S.T.A.L.K.E.R.: Call of Prypiat
作为第二款支持DX11技术的游戏,《S.T.A.L.K.E.R.: Call of Prypiat》(潜行者:普里皮亚季的召唤)已于2009年11月中在德国、奥地利、瑞士三个国家先行上市销售,明年第一季度再登陆北美、英国和其他欧洲国家。该游戏此番发行了两个版本,一是普通的标准版,然后就是限量收藏版了,采用金属包装盒里,里边除了游戏本身还有一张A3地图,以及相关主题的打火机、徽章、头巾等小礼物。

>>游戏类型:DirectX11 第一人称视角射击游戏
>>
>>画质设定:全部最高

DX11测试-Heaven Benchmark 1.0
● Heaven Benchmark 1.0
《Heaven Benchmark 1.0》是由俄罗斯Unigine游戏公司开发设计的一款Benchmark程序,该程序是由Unigine公司自主研发的游戏引擎设计,其支持DirectX 9、DirectX 10、DirectX 11与OpenGL 3.2 API,通过23个场景的测试最终得出显卡的实际效能。

>>游戏类型:DirectX 9/10/11及OpenGL Benchmark
>>
>>画质设定:全部最高


DX11测试-Heaven Benchmark 2.0
● Heaven Benchmark 2.0
《Heaven Benchmark 2.0》是由俄罗斯Unigine游戏公司开发设计的一款Benchmark程序,该程序是由Unigine公司自主研发的游戏引擎设计,其支持DirectX 9、DirectX 10、DirectX 11与OpenGL 3.2 API,通过26个场景的测试最终得出显卡的实际效能。
Heaven是款不错的DX11 Benchmark程序,其1.0版本是基于HD5000而开发的,Tessellation只有Normal级别。在GTX480发布之后,很快就诞生了2.0版本,其测试场景并没有太大变化,最核心的内容就是将Tessellation提升至Extreme级别。
>>游戏类型:DirectX 9/10/11及OpenGL Benchmark
>>
>>画质设定:全部最高


HD5000黄金架构测试回顾与总结
● HD5000黄金架构测试回顾与总结
在现有的几款DirectX 11游戏实际应用上,真正最强的DirectX 11单卡为Radeon HD 5970。虽然在DirectX 11理论性能测试中,Fermi架构的GeForce GTX 400系列表现抢眼,甚至在一些项目上秒杀A卡。但是毕竟Fermi架构拥有大量的曲面细分单元,取得这样的成绩是理所应当的。
那么现在和不久的将来一段时间内,DirectX 11显卡市场会有何动向呢?
● DirectX 11显卡现状
目前市场中只有AMD的中高低端DirectX 11显卡产品,其产品线从399元一直延伸至4000元,丰富的产品线可以满足用户各个价位上的需求。虽然目前DirectX 10和DirectX 11显卡市场均有售,但是在同样价位上选择功能更多的产品才是上上策,例如AMD的DirectX 11产品。

反观NVIDIA方面,虽然已经发布了DirectX 11相关产品,但仅为两款最顶级型号GeForce GTX 480和GeForce GTX 470,二者的市场零售均价为3888元和2888元。上述二者的性能不言而喻,但并非主流级用户所能触及,不过对于高端玩家来说二者不乏是一个不错的选择,毕竟NVIDIA的PhysX、CUDA 2.0等非常吸引人。
当然,GeForce GTX 400系列的高温、高功耗诟病让人烦恼。 综上所述对于目前市场来说高端市场选择余地较大,毕竟AMD和NVIDIA均推出了相关产品,而向下延伸的千元以及入门级产品仅有AMD产品可选。而且值得一提的是,GeForce GTX 400系列出现并没有真正对Radeon HD 5000系列造成价格压力,所以Radeon HD 5000系列价格将会在近期保持坚挺,如果有想购买DirectX 11产品的用户,现在是一个不错时机。
NVIDIA在最近3年中更新了3次GPU硬件架构,它们分别是:
● 面向DirectX 10游戏设计以G80G92为主的第一代统一渲染架构
● 面向游戏和通用计算并重的GT200架构(不包含GT210 220 240)
● 面向大规模并行计算和游戏并重的Fermi GF100架构
而ATI在最近3年中,成功推出了4款GPU硬件架构,它们分别是:
● HD2000系列第一代统一渲染架构
● HD3000系列平衡和改进型统一渲染架构
● HD4000系列扩张型优化后端和增添LDS缓冲架构
● HD5000系列支持DirectX 11放大版优化通用计算统一渲染架构
越来越多的测试和市场反应已经表明,AMD蛰伏了3年之后,终于在HD5000系列中全面获胜,同时在产品的性能和功耗方面找到了平衡点,为用户提供了更好的每瓦特性能。
事实上AMD在2005年发现了芯片规模的迅速增长对于功耗和发热的压力问题,并逐步提高重视程度着手解决。在GPU产品模块化设计的时代,衡量不同架构和工艺之间的关系已经成为一个重要并难以解决的问题。在这一点上,众多的评测数据特别是每瓦特性能这个指标,已经证明了AMD近几年间的路线。
- 相关阅读:
- ·GPU架构师升任院士 AMD变身显卡企业?
//vga.zol.com.cn/555/5554691.html - ·AMD下代R400系列GPU架构曝光:效率大增
//vga.zol.com.cn/548/5480371.html - ·AMD新一代Zen架构或将分为两种纳米工艺
//vga.zol.com.cn/546/5465091.html - ·野心乍现:三星未来将使用自主架构GPU
//vga.zol.com.cn/544/5447341.html - ·黄金品质 迪兰 R9-380 酷能售价1599元
//vga.zol.com.cn/541/5417765.html