RADEON X1000系的Pixel Shader结构——Pixel Shader Core

表面上看的话,RADEON X1000系的Pixel Shader非常非常类似于R420,所不同的是,主要是增加了一个分支单元,并且计算精度从原来的FP24提升到了Shader Model 3.0要求的FP32。
在每个周期里,X1000系各个Pixel Shader处理器能够跑5条指令:
1条vec3 ADD指令(Vector ALU1)
1条scalar ADD指令(Scalar ALU1)
1条vec3 ADD/MUL/MADD指令(Vector ALU2)
1条scalar ADD/MUL/MADD指令(Scalar ALU2)
1条流控制指令
此外,由于采用的是R300以来就使用的独立纹理单元,因此在遇到纹理操作的时候,X1000系的Pixel Shader一共最高能执行5条Pixel Shader指令和1条纹理操作指令。
相比之下,NVIDIA的GeForce 7800的Pixel Shader又如何呢?
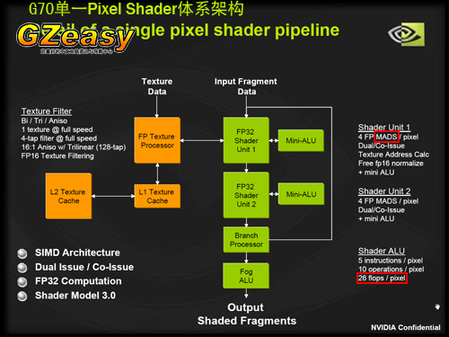
在上图中,我们可以看到G70拥有两个能运行MADD指令的4D ALU,这两个ALU都能以4D、1D/3D或者2D/2D的方式完成指令,在运算能力上要强于R520。同样的频率下,G70的每个pixel shader能完成16FLOPS(FP32),而R520就最多只能做到12FLOPS(FP32),如果遇到相邻两条MADD指令或者相邻的MUL指令+MADD指令的话,R520就只能做到8FLOPS,是G70的1/2。此外,G70的ALU1还能够免费地执行一条FP16的nrm指令,nrm指令是用于计算法线的,对于Unreal Engine3中大量使用Normal Mapping计算有明显的加速作用。
但是和R520相比,G70又存在一个不足,那就是ALU1兼负了纹理寻址计算(例如纹理坐标透视纠正的计算),在遇到纹理操作的时候,ALU1就不能自行像素着色器指令转而执行纹理操作指令,只剩下ALU2能够跑像素着色器指令。不过现在的游戏程序中,纹理操作的指令数量基本上都是低于像素着色器指令的数量,因此NVIDIA这样的设计也不失其合理性。
 就为那一抹红 iGame GTX 1660 Ultra图赏
就为那一抹红 iGame GTX 1660 Ultra图赏 A卡真旗舰 蓝宝石RX 5700 XT 超白金图赏
A卡真旗舰 蓝宝石RX 5700 XT 超白金图赏 华硕P8Z77-V DELUXE新功能解析
华硕P8Z77-V DELUXE新功能解析 全汉蓝暴经典版550电源评测
全汉蓝暴经典版550电源评测