在本页阅读全文(共14页)
采用全相联技术提高cache命中率
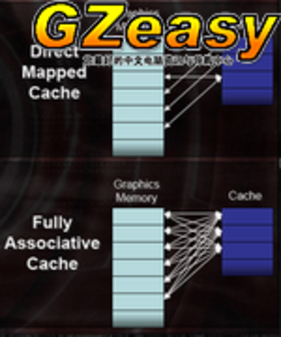
上述的内存控制技术虽然都能降低延迟,但是内存存取动作还是应该尽量避免,把重复使用的数据存放在GPU的cache内就是减少内存存取动作的重要技术。
ATI表示,在以往的GPU上采用的cache都是直接映射(direct map),即每个cache的入口都映射至一块专门确定了的图形内存区块。虽然这可以让cache的执行简单化,但是当出现内存客户端需要交换两个数据,而这两个数据刚好要位于被cache映射的同一块内存内,那么这两块数据就需要不断地将彼此挤出cache,这样的话在写数据的时候就可能会产生迟延(stall),显著降低cache的命中率,增加了内存存取的压力。
而ATI在RADEON X1800的纹理cache、z/stencil cache、色彩缓存cache上就采用了全相联的cache技术,cache不再只是映射到特定一个或者某几个的内存地址,而是任意空闲的内存。ATI表示,在任何给定的时钟频率下的内存带宽敏感型应用中(例如在高分辨率下打开全屏抗锯齿和各向异性过滤),X1800的性能都能比采用前提升25%。
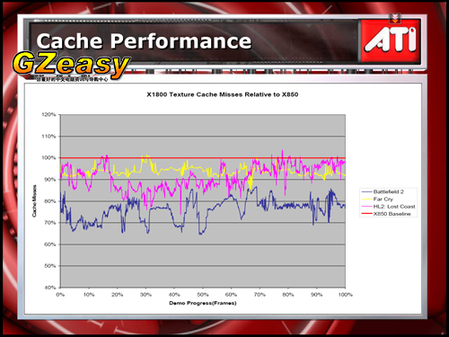
纹理高速缓存命中失败率比较(X1800 VS X850,以850为基准)

Z深度值高速缓存命中失败率比较(X1800 VS X850,以850为基准)
本文导航
 就为那一抹红 iGame GTX 1660 Ultra图赏
就为那一抹红 iGame GTX 1660 Ultra图赏 A卡真旗舰 蓝宝石RX 5700 XT 超白金图赏
A卡真旗舰 蓝宝石RX 5700 XT 超白金图赏 华硕P8Z77-V DELUXE新功能解析
华硕P8Z77-V DELUXE新功能解析 全汉蓝暴经典版550电源评测
全汉蓝暴经典版550电源评测